DevOps Transformation Plan: Step-by-Step Guide to Modernizing Your Software Delivery
6 min read• Nov 12, 2025
Written by

Milestone Team

Release cycles for modern software are measured in days, not months. Users want new features, security updates, and performance improvements as soon as possible. Stage-gate workflows that move code from development to operations in a straight line create bottlenecks, increasing the likelihood of defects in production.

That’s why more and more businesses are putting a clear DevOps transformation plan into action: it brings together people, processes, and tools so that code can move smoothly from idea to production.
In short, DevOps enables engineering teams to deliver reliable software at the speed required by today’s digital market, without compromising security or stability.
DevOps transformation is the shift from siloed development and operations to a single, streamlined workflow that supports continuous delivery and small, safe releases that reach users quickly.
Why DevOps matters today
Together, these changes reduce release risk, speed up delivery, and give teams a single view of product health.
The seven steps below outline a straightforward path from ad-hoc releases to reliable, automated delivery.
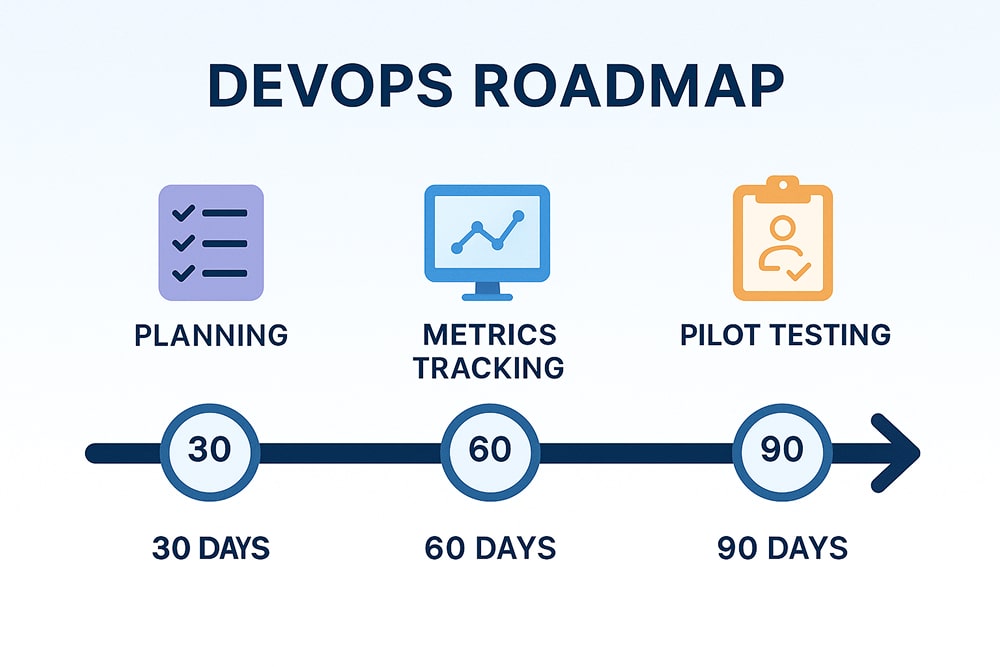
Document the real bottlenecks first, then translate them into short, timed objectives.
Outcome: Everyone sees the plan, metrics are baseline, and small wins fund the next stage.
Move workloads onto predictable, self-healing platforms so environments stop drifting.
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: namespaces-must-have-team
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
labels: ["team"]Targets: Cluster bootstrap in <5 min; nightly config drift <3 percent.
Turn every commit into a tested, versioned artifact that rolls forward or back without manual work.
Minimal CI job:
name: ci
on: [push]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-go@v5
with: {go-version: "1.22"}
- run: go test ./... -coverprofile=cover.out
- run: docker build -t ghcr.io/org/api:${{ github.sha }} .
- uses: aquasecurity/trivy-action@v0.22
with: {image-ref: ghcr.io/org/api:${{ github.sha }}KPI: ≥5 production deploys per day; MTTR ≤30 minutes.
Give every role the same objectives and visibility.
When developers carry the pager and Ops join code reviews, incentives align.
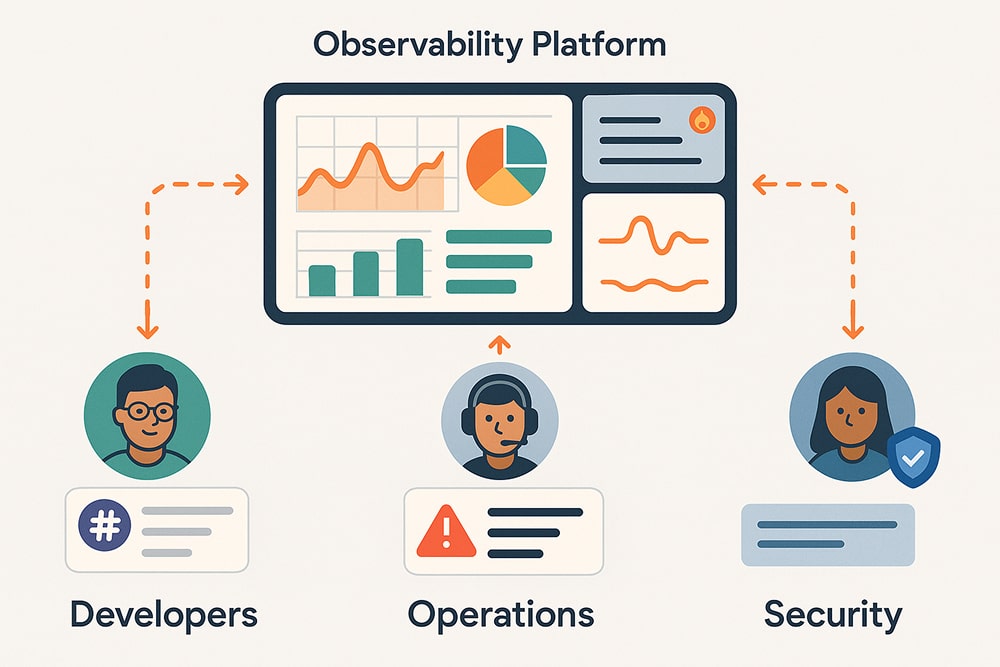
Collect actionable data, alert early, and feed findings back into sprints.
These signals drive backlog items for resilience and performance, eliminating the need for guesswork.
Bake security into the same pipeline that runs tests.
Security moves left, risk drops, and audit evidence lives in Git.
Systematize the gains and keep learning.
These loops-self-service, chaos, feature flags, cost checks, and game days-keep the platform healthy and evolving long after the initial DevOps transformation plan is complete.
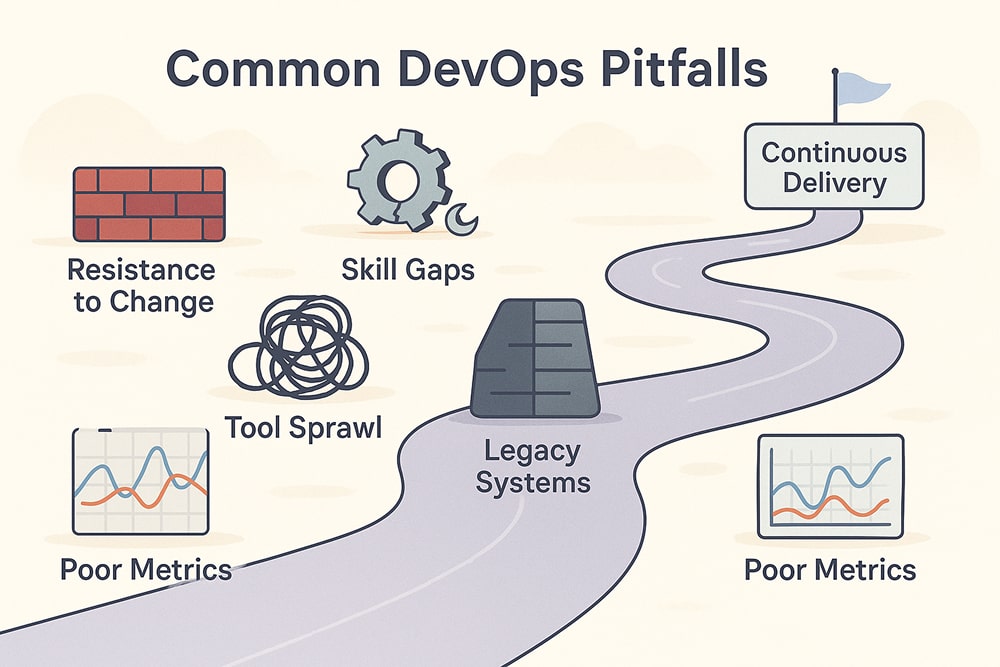
Limited automation, fragmented toolchains, and legacy infrastructure typically slow progress. Start small, celebrate wins, and secure leadership buy-in.
Track North-Star metrics: deployment frequency, lead time for changes, MTTR, and change failure rate. Improvement across these indicates healthier flow.
Re-evaluate quarterly or sooner if KPIs don’t progress, business priorities shift, or new regulations emerge.
Find the places where things go wrong (like slow builds). Test one tool that fixes the biggest problem, demonstrate its effectiveness, and then add more.
It encourages shared ownership, learning without blame, and faster feedback, which breaks down the barriers between Dev and Ops.
A disciplined DevOps journey delivers speed with stability. By following this step-by-step framework, tracking outcome-based metrics, and promoting continuous learning, engineering teams can modernize software delivery and lower operational risk. When additional expertise is required, partnering with experienced DevOps transformation services helps accelerate progress and sustain momentum.
Sign up to our newsletter
By subscribing, you accept our Privacy Policy.
