KTLO in Engineering: From Maintenance to Strategic Advantage
7 min read• Apr 08, 2026
Written by

Milestone Team

KTLO stands for Keep The Lights On. In a modern engineering organization, it is the work that keeps production reliable while the product continues to evolve. It includes the care and attention that prevents small issues from turning into outages, security risks, or slow delivery. Engineers often experience KTLO through incident response, routine maintenance, and the steady stream of fixes that keep systems stable under real traffic.
Many teams still treat KTLO as a cost center because it does not ship an obvious new capability. That view is short-sighted. An unmaintained system does not stay the same. It becomes harder to change, harder to operate, and easier to break. Over time, feature work starts to pay off past shortcuts.
The better framing is strategic. KTLO is how you build resilience, earn trust, and sustain velocity without burning out the team.
KTLO is the work that keeps an existing system healthy, secure, and dependable while the team continues to ship. It includes ongoing system maintenance and operational support, as well as response work when things go wrong, such as incident handling and root cause analysis. It also covers the quieter improvements that help prevent future incidents, such as refactoring to improve codebase health, reliability, and infrastructure scalability, and a deliberate reduction in technical debt. In a mature team, KTLO also includes security patches, dependency management, and performance work such as latency reduction and capacity tuning. These tasks do not usually create new product capabilities, but they protect the capabilities you already have and make future changes safer.
KTLO is not a new feature development. It is not greenfield initiatives, big innovation bets, growth experiments, or roadmap expansion work. Those efforts are about building something new. KTLO is about ensuring what you have continues to work, remains safe to change, and supports the next round of innovation. In that sense, KTLO is not stagnant. It is the foundation that makes innovation sustainable instead of fragile.
Neglect compounds. It rarely fails loudly at first. It fails quietly, then expensively.
When KTLO work gets deferred, you tend to see:
This is why KTLO is best understood as a proactive investment. You are paying a smaller, predictable cost to reduce a larger, unpredictable one. You are also preserving velocity; you cannot move fast if your team spends its best hours responding to pages, chasing flaky tests, and patching known risks under pressure.
The strategic impacts are easy to map:
KTLO lowers outage probability and reduces blast radius. Examples include tightening rate limits, removing single points of failure, improving rollback paths, and shrinking dependency risk.
Stable systems behave predictably under load, during deploys, and during partial failures. That predictability is what makes planning credible.
Every avoidable incident steals time from feature work. Every slow build steals focus. KTLO removes friction so engineers can spend more time designing and less time surviving.
Customers rarely praise reliability, but they punish instability. Consistent service delivery builds trust, and trust becomes retention.
This is also where economics matter. Prevention is often cheaper than recovery. A dependency patch during a planned sprint is controlled. A dependency patch during a live incident is rushed, risky, and disruptive. Even if you never attach an exact dollar value, the pattern is consistent: the cost curve bends upward when you wait.
A lot of teams talk past each other on KTLO because the same term gets used for two different things. One is technical system care. The other is delivery coordination. If you do not separate them, KTLO becomes a vague bucket that is easy to dismiss.
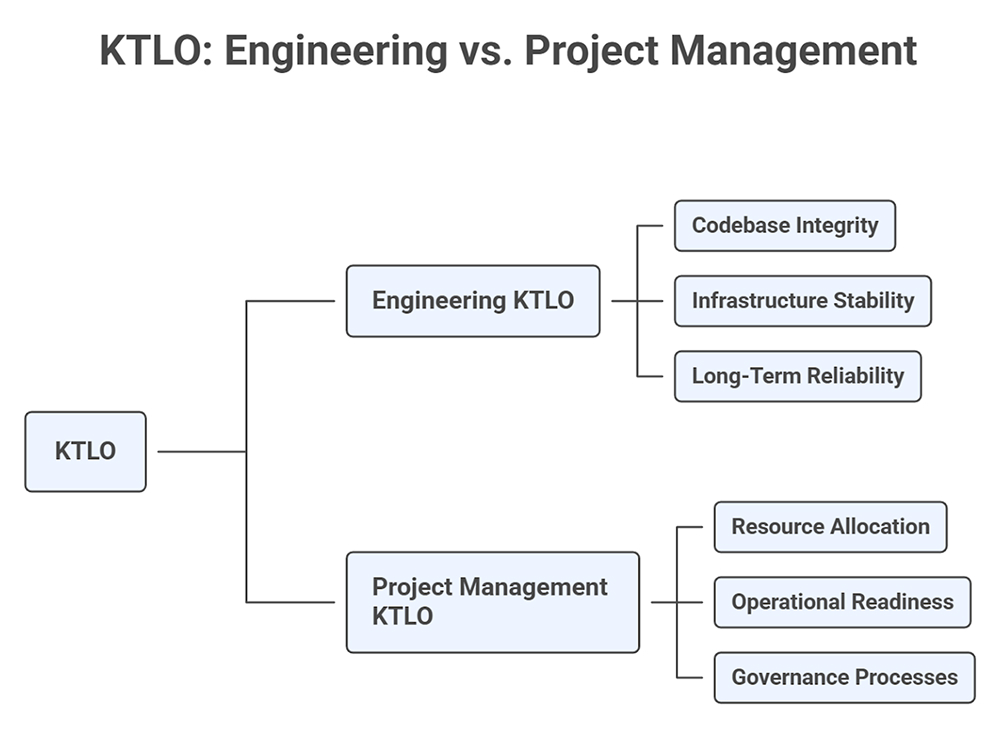
In engineering, KTLO is about keeping the product technically viable. It focuses on the health of the systems that run in production. That means codebase integrity, infrastructure stability, and long-term reliability. It is the work that keeps deployments safe, reduces incident frequency, removes brittle dependencies, and keeps performance and security within acceptable bounds. The output is a system that can handle real load and can be changed without fear.
In project management, KTLO refers to the planning and coordination effort required to keep delivery moving. It includes resource allocation, operational readiness, and governance processes. This work can be important in larger organizations. It helps teams align on scope, sequencing, risks, and ownership. Still, it does not directly improve production reliability or reduce technical risk as engineering KTLO does.
When these two meanings get conflated, technical KTLO often loses. Leaders see the KTLO label and associate it with general overhead. It gets grouped with meetings, reporting, and status management. Then, during prioritization, the easiest way to “increase delivery” seems to be cutting KTLO. What actually happens is the opposite. Cutting technical KTLO increases incident load, makes change riskier, and slows feature delivery through interruptions and rework. Engineering KTLO is not about keeping a process running. It is about protecting the product itself, so it remains stable enough to grow.
KTLO is often undervalued because success looks quiet. A clean week in production does not produce a demo. A patched dependency does not show up in a roadmap review. But the value is real, because it prevents disruption and preserves speed.
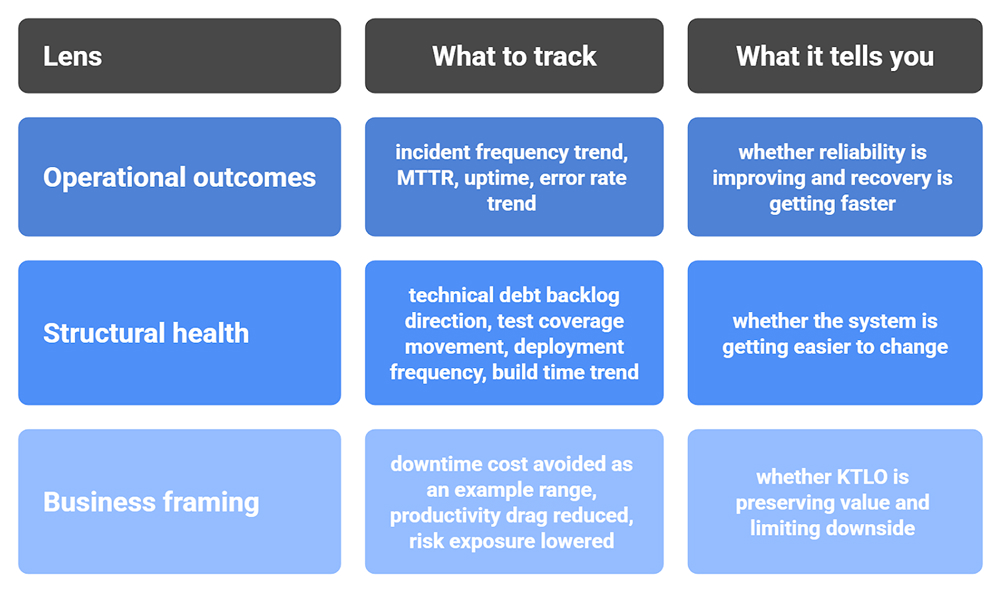
A practical way to make KTLO visible is to tie it to outcomes that matter to both engineering and the business. Use a small set of signals, track the trend over time, and connect the trend to risk reduction and improved health delivery.
The key is the framing. This is not non-feature work. It is value preservation and risk mitigation. It keeps your delivery machine from losing efficiency as the system grows.
The tension is real: every team has a backlog full of features and system health work. If you only prioritize features, the system decays. If you prioritize KTLO alone, you risk underdelivering on business value. The goal is not perfect balance; the goal is deliberate balance.
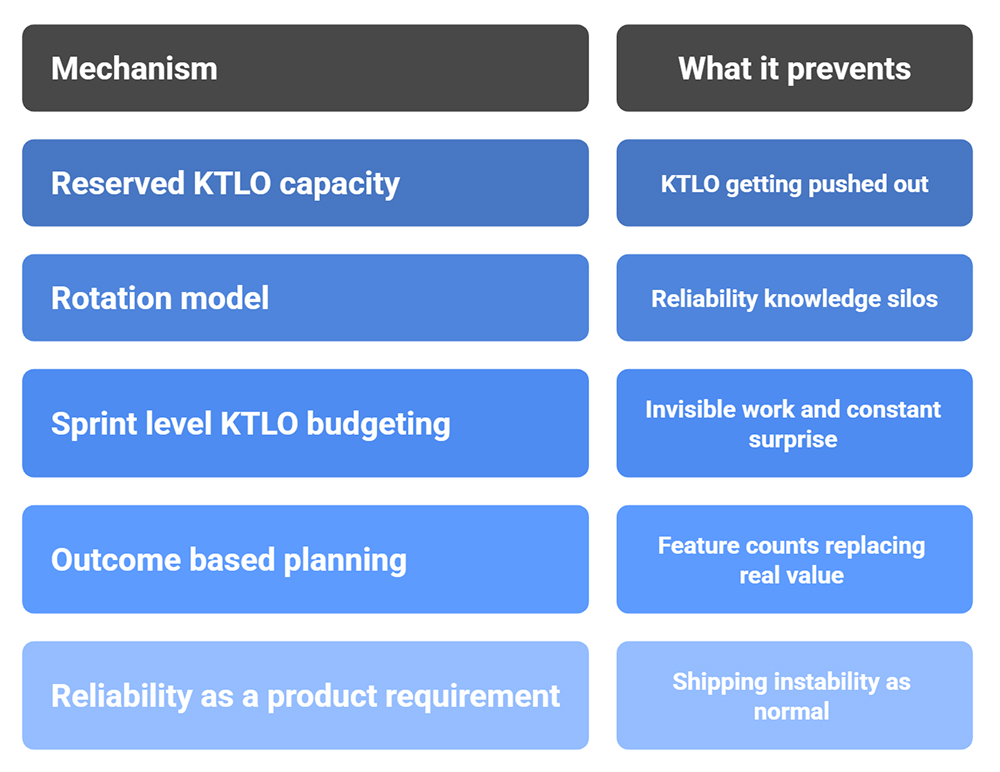
Many organizations reserve a fixed slice of capacity for KTLO. Common ranges are 20-40%, depending on system maturity and incident rates. Early-stage products may need more stability work than leaders expect, because every architectural shortcut is still fresh and sharp.
A rotation can work well if it is supported properly by:
Rotations fail when a team member becomes “the person who handles problems” without authority to schedule prevention work.
If you plan sprints, plan KTLO explicitly. Not as leftovers. Allocate items with clear goals. A sprint that includes one reliability outcome can often ship features faster in the next sprint because your pipelines and systems stop fighting you.
This is where many teams shift their mindset. Instead of measuring output only by shipped features, measure by outcomes like:
When these outcomes are valued, KTLO stops being a “tax” and starts being part of how you ship.
If a product needs 99.9 availability, that is a requirement, not a wish. The same applies to security posture, data retention guarantees, and performance expectations. Treating these as requirements ensures KTLO is part of planning, not an afterthought.
This is also where teams discuss KTLO mode: a period in which reliability work becomes the primary focus because the system has reached a risk threshold. Used sparingly and intentionally, it can prevent bigger failures later.
KTLO is not low-value maintenance. It is the operating discipline that lets organizations scale, ship faster over time, and recover gracefully from failure. When well-managed, it reduces operational load rather than adding overhead. It becomes strategic infrastructure for durable performance.
Teams that invest in KTLO tend to see compounding benefits. They move faster in a way that they can sustain. They build customer trust through consistent service. They reduce systemic risk by shrinking failure paths and removing recurring causes of incidents. They improve developer experience by reducing constant interruptions. Over time, they create long-term engineering leverage because the system stays healthy as it grows.
KTLO includes operational maintenance, incident response, and root cause analysis, security patching, dependency management, performance improvements, reliability work, refactoring, and technical debt reduction. It covers the work that keeps production stable and safe so that new development can happen without constant firefighting.
The standard healthy range is approximately 20-40% engineering capacity. This is adjusted for maturity and incident rate. If you have frequent outages or risky deployments, you may need more. However, if your system is stable and automated, you can lower them without the risk of increasing.
Using operational metrics and business framing, break down incident trends, recovery time, uptime, error rate, deploy frequency, build time, and downtime cost-avoided KTLO items to reduce risk and reclaim dev time. The story is about value preserved, not features lost.
KTLO in engineering is technical system health: code quality, infrastructure stability, reliability, security, and performance. In project management, KTLO is responsible for delivery operations: planning, coordination, governance, and resource allocation. Mislabeling them can obscure the value of technical KTLO by treating it as generic overhead.
Prioritize KTLO based on risk and customer impact. Use capacity allocation, sprint budgeting, reliability ownership, and outcome-based planning to compete fairly with features. Treat reliability targets as product requirements. When risk spikes, a focused KTLO mode can restore stability faster.
Sign up to our newsletter
By subscribing, you accept our Privacy Policy.
