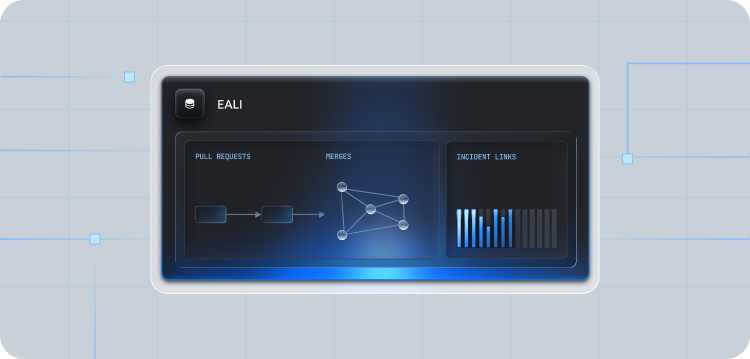
The assessment distortion emerging in agentic engineering resembles a well-known challenge in evaluating data science teams.
Data scientists typically operate in environments characterized by high tool interaction, sparse visible artifacts, and large variance in impact. A data scientist may execute hundreds of exploratory runs, adjust features iteratively, and discard numerous intermediate models, yet produce only a small number of visible outputs. The measurable artifact (a model, a dashboard, a report) represents the end state of a long sequence of invisible decisions.
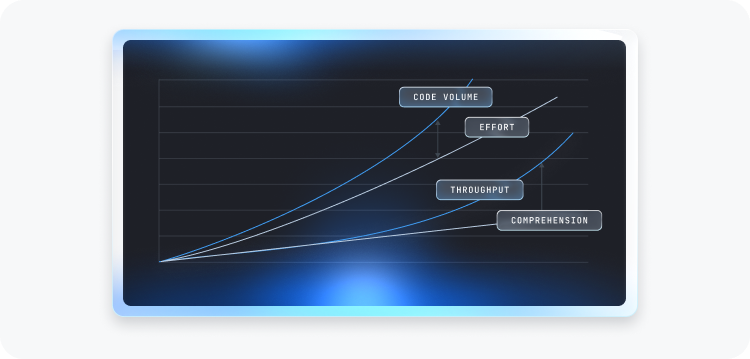
As a result, performance cannot be inferred from superficial activity signals. Lines of code written, notebook cells executed, or hours spent in experimentation are weak proxies for value. Instead, leverage resides in upstream activities: problem framing, feature selection, hypothesis discipline, error containment, and the capacity to avoid unproductive paths. The contribution profile is highly non-linear. Small conceptual decisions can have disproportionate downstream consequences, while high volumes of activity may produce little lasting impact. Evaluation therefore shifts from measuring mechanical output to assessing the quality of decision-making under uncertainty.
Agentic engineering increasingly exhibits similar characteristics.
As AI systems assume more of the mechanical work of implementation, engineers spend less time constructing systems from first principles and more time shaping intent, defining constraints, supervising generation, and resolving exceptions. Code becomes, in many cases, the artifact of orchestration rather than direct authorship.
This shift introduces a second-order assessment problem: tacit system knowledge becomes harder to observe and harder to account for within performance and governance frameworks.
In traditional development environments, engineers accumulated architectural intuition through sustained immersion in specific subsystems. Although tacit knowledge was never directly measurable, it was indirectly visible through patterns of engagement; depth of contribution, continuity of ownership, and involvement in review and incident response. Interaction served as a rough proxy for understanding.
As mechanical interaction decreases, that proxy weakens. Engineers may traverse more of the system while spending less time constructing any single part of it. Engagement becomes broader but shallower. Tacit knowledge may still develop, but under different conditions and with fewer observable signals.
This dynamic parallels the data science problem. In both cases, the most consequential work occurs upstream of visible artifacts. In both cases, traditional activity signals become unreliable indicators of capability. The measurement distortion is not that output disappears, but that output no longer reflects where leverage and understanding actually reside.
In this setting:
- Engineers shape constraints rather than write every line.
- They supervise generation rather than construct incrementally.
- They intervene selectively rather than continuously.
- They allocate trust across tools and workflows rather than execute each step manually.
As implementation becomes partially automated, performance variance shifts upstream. It resides in specification clarity, supervision depth, escalation timing, and risk containment discipline. The visible artifact, such as the merged pull request, may conceal substantial invisible iteration and judgment.
The analogy, however, has limits.
Data science is typically exploratory and probabilistic; agentic engineering is operational and cumulative. Data science outputs are often bounded experiments; engineering changes integrate into long-lived systems with ongoing dependencies and governance obligations. The risk profile of engineering work is therefore structurally higher. A flawed model can be retrained; a flawed system change may accrete dependencies and become economically irreversible.
The analogy is therefore not about domain equivalence, but about measurement structure.
In both domains, observable output becomes a weak proxy for leverage when upstream reasoning and tool mediation dominate the production process. In both, the most consequential contributions occur in how constraints are defined and how risk is contained rather than in the mechanical act of construction.
For engineering leadership, this reframes the central assessment challenge. The question is no longer whether AI produces “good code,” nor whether engineers are active, but whether the organisation can still observe and evaluate leverage under conditions of mediated production.
If engineering work increasingly consists of high-leverage inputs applied to generative systems, then measurement must shift accordingly. It must capture not only what is produced, but how safely and sustainably acceleration is absorbed by the organisation.
In this sense, the data science analogy provides a frame of reference: performance becomes less about visible effort and more about calibrated amplification. The task of assessment is to distinguish raw acceleration from controlled acceleration.
That distinction motivates the leverage model introduced in the next section.