Modern Software Development Governance: From Rules to Real-Time Oversight
7 min read• Mar 11, 2026
Written by

Milestone Team

Most engineering teams are cautious about governance practices because they often feel like a source of friction. This is because activities like pre-release reviews and checklist adherence are perceived as overhead on top of the work they are already doing. At the same time, with modern practices, delivery has accelerated. Teams ship more often, depend on third-party code, and run cloud systems that change constantly. In that world, governance can’t live in static documents or quarterly reviews. It has to operate at delivery speed, close to where changes happen.
Think of it this way. Governance isn’t a gate at the end; it’s guardrails on the road that help teams move fast without losing control. The goal is simple. Reduce surprises in production, keep security and compliance from becoming last-minute panic, and make “doing the right thing” the easiest path for developers. When governance is designed well, it doesn’t interrupt delivery. It quietly supports it.
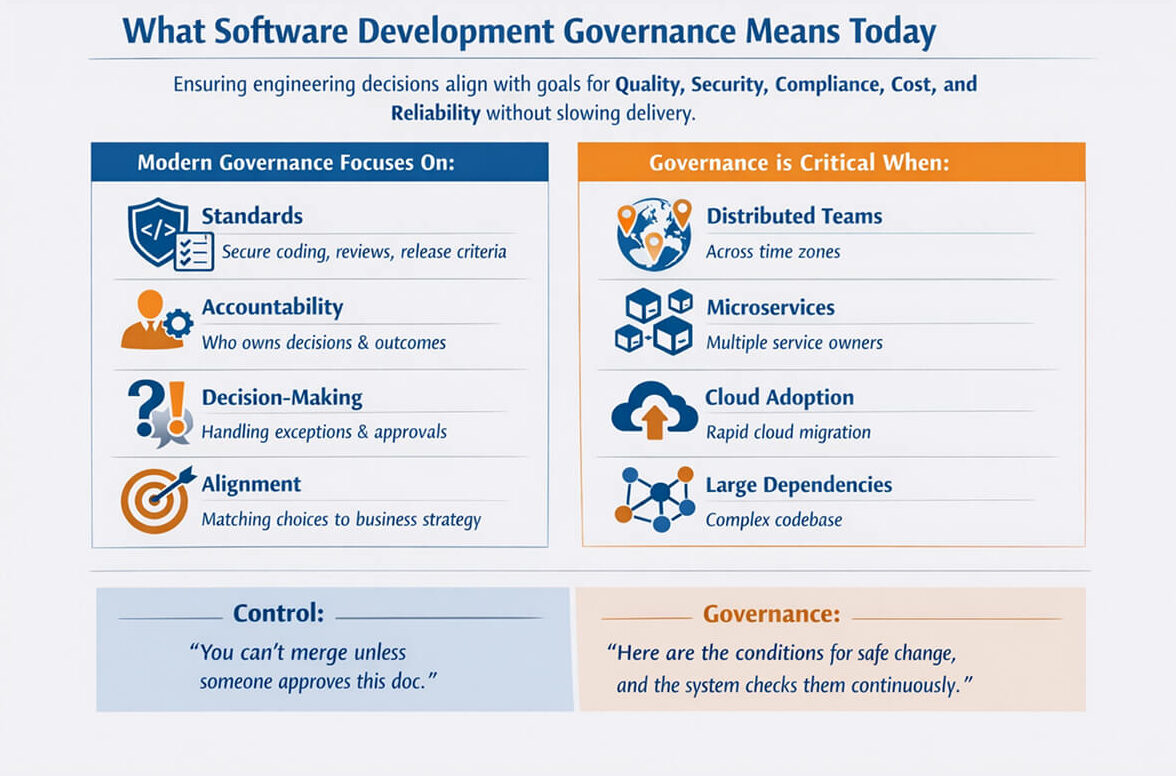
Software development governance is the framework you use to ensure engineering decisions align with your organization’s goals for quality, security, compliance, cost, and reliability without slowing delivery.
In practice, modern governance focuses on:
Therefore, governance becomes especially important for modern teams distributed across time zones that build high-change, high-frequency systems. It’s also important to distinguish between governance and control. Control says, “You can’t merge unless someone approves this doc.” Governance says, “Here are the conditions for safe change, and the system checks them continuously.”
You can’t “monitor” your way out of structural problems. Software architecture governance establishes shared technical guardrails, enabling teams to build systems that remain scalable, observable, and maintainable without forcing every project through a heavyweight review board. Good architecture governance typically defines:
This isn’t about building the perfect architecture. It’s about reducing chaos and drift while keeping teams autonomous.
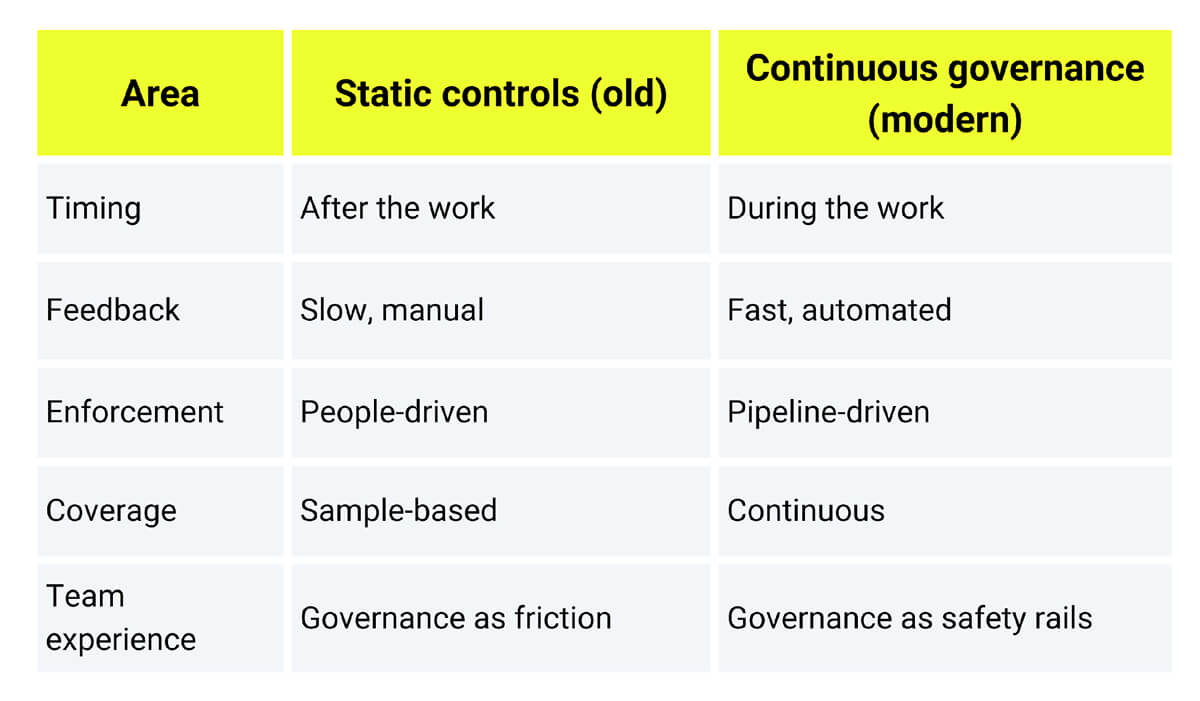
Traditionally, governance relied on static controls such as periodic audits, manual checklists, approval workflows, and architecture review meetings. These approaches break down in modern delivery because they’re batch-oriented. They detect problems late, when fixes are expensive, and people are already context-switched. Continuous governance flips the model on its head by measuring compliance in real time through automation.
It also reduces noise by escalating only when risk crosses a defined threshold. This is the “real-time oversight” shift, where you move from reviewing intentions to verifying reality.
Modern tools and frameworks increasingly support this direction, including policy engines such as the Open Policy Agent (OPA), which aims to unify policy enforcement across the stack by treating policies as code.
Static vs. Continuous Governance
A software governance framework is the operating system for your engineering decisions. It includes policies, roles, workflows, and metrics that keep delivery safe and aligned without turning engineering into paperwork. The best frameworks share a few traits:
Policies should be concise enough to understand in a single pass and testable so you can verify them with tooling or evidence. Most importantly, policies need to be outcome-driven and serve a purpose. Below are several policies you can enforce and measure simultaneously.
The key is clarity. If a policy triggers debates like “what does this really mean?” it will be applied inconsistently. Inconsistent governance is worse than no governance, as it gives a false sense of safety.
Once your policies are clear, the next step is simple. You have to stop relying on humans to remember them. Manual governance creates two problems when it scales poorly: it introduces delays when teams are trying to ship. Automation fixes both of these issues.
When governance is integrated into CI, teams receive early feedback before deployment, and enforcement becomes consistent across repos and teams. This is where policy-as-code fits naturally. You encode the rule in a machine-evaluable format and run it against real inputs, such as Terraform plans, Kubernetes manifests, or build configurations.
Open Policy Agent (OPA) is a common approach that lets you write policies in a high-level declarative language (Rego) and evaluate them against structured inputs, enabling the pipeline to decide “allow or deny” (or warn) based on rules. The practical win is that governance becomes repeatable and auditable without becoming a manual approval workflow.
Even with strong policies, exceptions will arise, such as urgent production fixes, legacy constraints, or time-sensitive releases. The mistake is treating exceptions as rare, informal “one-offs.” If exceptions live in private chats or ad hoc approvals, they become invisible, and these invisible exceptions persist. Over time, governance quietly erodes. A good governance framework treats exceptions as a normal, controlled process. That means defining:
The goal is to build transparency, even for exceptions, so that tracked exceptions become useful feedback, highlighting where policies are unrealistic or where teams need a safer, approved path.
Real-time governance doesn’t mean sitting in front of dashboards all day. It means your toolchain continuously answers questions like “Are we drifting from approved architecture patterns?” or “Are critical vulnerabilities increasing?” A simple reference stack for real-time oversight might include:
Supply chain security frameworks, such as SLSA (Supply-Chain Levels for Software Artifacts), also reinforce the importance of integrity controls throughout the pipeline, helping prevent tampering and improving artifact trust.
Policy Check in CI (Example)
Below is a simplified example of how teams embed governance into CI using a policy step for better understanding.
# Example: CI step running policy checks (conceptual)
name: policy-check
on: [pull_request]
jobs:guardrails:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v4
- name: Validate IaC and config against policiesrun: |
# Example: evaluate policies against Terraform plan or Kubernetes manifests
opa eval --format pretty --data policy/ --input build/input.json "data.guardrails.allow"OPA is commonly used as the policy engine behind this type of workflow.
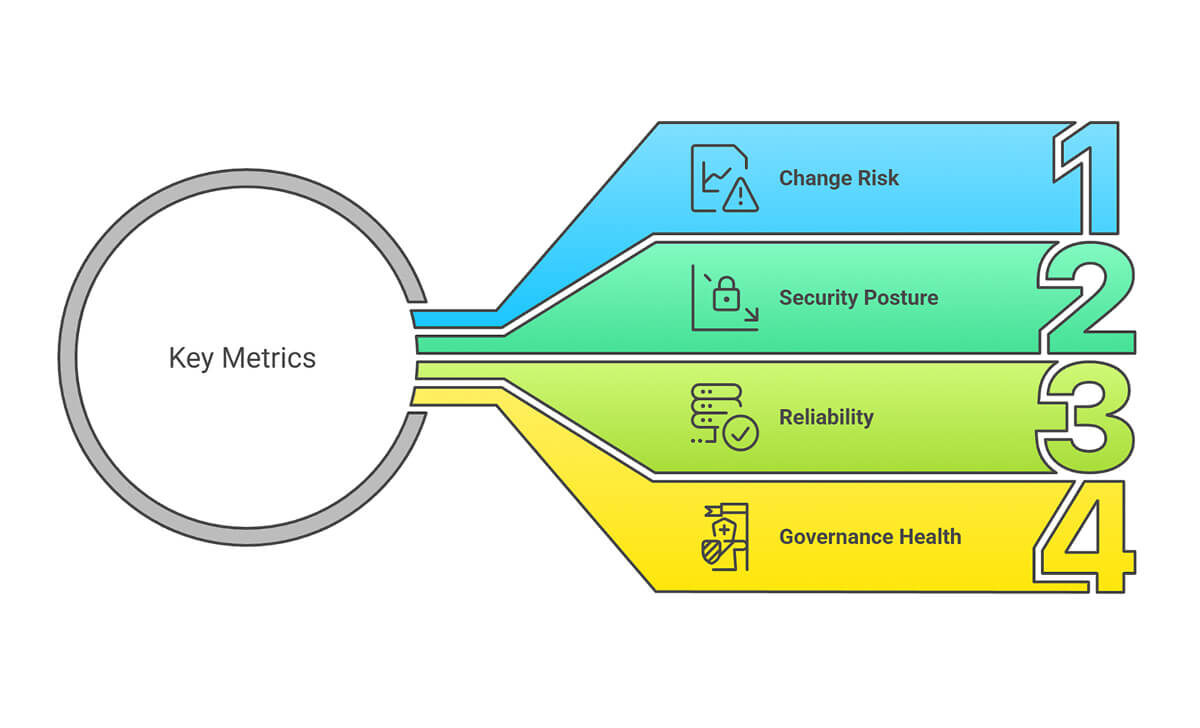
It’s important to understand that it’s not about the number of metrics you track. You only need a few that change behavior. A good set of metrics to start with includes:
Change risk
Security posture
Reliability
Governance health
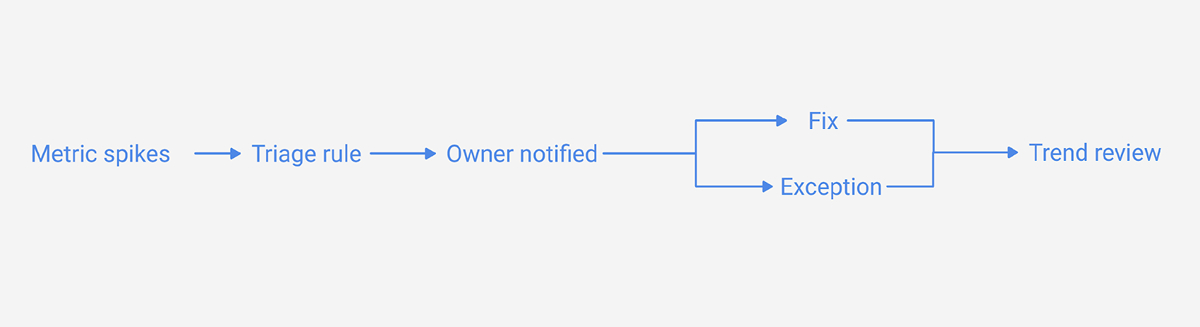
If you can’t tie a metric to a decision (“What do we do when this spikes?”), it’s likely noise.
Diagram 3 (Suggested): “Metrics – Decisions”
Purpose: connect measurements to action.
Modern governance has one job: to help teams move fast without making the system fragile. To do that, you have to move away from rigid, manual controls and toward continuous, automated oversight, where policies are testable, checks run in the pipeline, and decisions are guided by real signals rather than by occasional review meetings.
When implemented well, governance doesn’t feel like a barrier-it fades into the background while its benefits show up everywhere: teams ship with confidence, architecture remains coherent, risks surface early, and compliance evidence is generated naturally as part of everyday delivery.
If you want to explore the broader landscape, the Kiuwan overview and the 3Pillar discussion are good starting points for understanding how governance frameworks are applied in practice.
Usually, it’s a shared responsibility: engineering leadership sets direction, platform teams embed checks in pipelines, security defines risk controls, and senior engineers help shape architectural standards. The key is making governance engineering-led rather than purely compliance-led.
It can if governance is implemented as manual gates and late-stage approvals. But when governance runs early (in CI) and uses automation, it often increases velocity over time by reducing rework, outages, and emergency fixes. The difference is whether governance detects issues before or after deployment.
It scales through consistency and automation. Distributed teams don’t need more meetings; they need shared baseline rules, visible exceptions, and tool-driven enforcement that is consistent across repos and environments.
Start with policy-violation trends, exception volume and duration, time-to-fix for critical security issues, and change-related reliability signals (rollbacks and incidents tied to deploys). These are measurable, hard to argue with, and directly tied to outcomes.
Sign up to our newsletter
By subscribing, you accept our Privacy Policy.