Every bug that reaches production wastes time, erodes trust, and distracts engineers from new work. Teams need a quick, objective way to check whether their delivery process is catching problems early enough. That’s where defect rates come in.
What is Defect Rate?
Defect rate is the proportion of confirmed defects found in a defined scope of work. To determine the defect rate, take the number of defects, divide it by the total number of items inspected (such as commits, test cases, or lines of code), and multiply by 100 to see the percentage of the work that had problems.
When you watch the defect rate trend sprint by sprint, you see whether reviews, tests, and safeguards are working instead of relying on gut feeling.
What Counts as a Defect?
A defect is any verified problem logged in your issue tracker, such as a failing acceptance test, a performance regression, a security issue, or a user-reported error. The definition must be uniform across teams to avoid metrics becoming noisy. So, agree on three simple characteristics to determine if something is a defect:
- The behavior is reproducible.
- The behavior violates an explicit requirement or an established standard (for example, a latency service level objective [SLO]).
- Someone creates a ticket that stays until it is either resolved or accepted as a “won’t-fix.”
These rules keep debates short and data-driven.
Why Use a Rate Instead of Raw Counts?
Raw bug counts grow naturally with team size and backlog scope, so they do not reveal efficiency. A rate normalizes the view, allowing for comparison over time or across services. Two common denominators are:
- Items tested: commits reviewed, stories completed, or test cases executed.
- Code size: measured in thousands of lines of code (KLOC) when you need to calculate defect density for deeper dives.
How to Calculate
Once you’ve defined what counts as a defect and chosen a consistent denominator, you can calculate the defect rate. In addition, you can calculate defect density and the percentage of escaped defects to show how defects scale with code size and how many slip into production.
Consider a service update that includes 2,700 lines of code, runs 55 automated test scenarios, and results in five defects during testing. Later, one more issue is discovered in production.
Defect rate
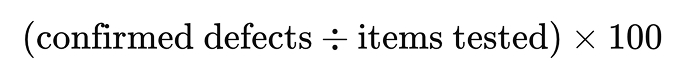
Shows the percentage of inspected work that contained defects.
(5 ÷ 55) × 100 = 9%
Defect density

Shows how many defects occurred per thousand lines of code. This helps compare modules of different sizes.
Total defects = 6 (including the production issue)
Code size = 2.7 KLOC
6 ÷ 2.7 ≈ 2.2 defects/KLOC
Escaped-defect percentage
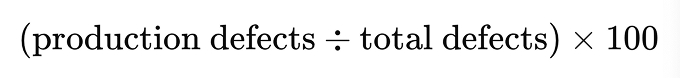
Shows what share of total defects were only found after release.
1 ÷ 6 × 100 ≈ 17%
How to Reduce Defects
- Shift checks left. Plug static analyzers or type checkers into the commit hook. They block obvious issues before code review.
- Keep pull requests small. A patch under 300 lines is easier to reason out. Reviewers can focus on intent rather than scrolling through noise.
- Strengthen unit tests. Aim for broad logic coverage first. Fast feedback loops prevent whole-day debugging sessions.
- Watch production signals. Add exception counters and latency alerts. Identifying silent failures early helps keep the escaped defect percentage low.
- Share visual trends. Plot the metric on the team wall or dashboard. Visible numbers nudge everyone to leave the codebase a little cleaner than they found it.
Common Mistakes and How to Avoid Them
- Changing the denominator mid-stream. If you switch from stories to commits halfway through a quarter, the graph resets. Decide once per planning cycle and stick to it.
- Logging only “big” bugs. Omitting minor issues makes every release appear perfect until production reports start to flood in. Record all defects; let severity labels separate simple ones from critical.
- Assuming zero is realistic. Aiming for zero defects in complex systems often leads to shipped workarounds and hidden risk. Set incremental targets and balance them against delivery goals.
Conclusion
Tracking defect rate replaces guesswork with clear evidence. You just need to collect the data that is already in your tracker and CI logs. Start today by capturing one week of numbers for a single service. Use the result to decide on a small next step. Continue this loop until the defect rate falls within your target range for several consecutive sprints. Gradually, it will reduce rework, keep releases predictable, and improve user trust.