Deep-learning models are skyrocketing in size, but that power comes at a cost: storage footprints grow, latency slows, batteries drain, and environmental impact climbs. Knowledge distillation (KD) tackles these headaches by transferring the “brains” of a large, accurate teacher network into a lightweight student network. The student is trained to imitate the teacher’s behavior, so it delivers nearly the same accuracy while running far faster on phones, drones, Internet-of-Things sensors, or embedded GPUs. In six concise sections, this article demystifies KD, explores its algorithms and training styles, and surveys real-world uses without tables or explicit calendar years.
What Is Knowledge Distillation?
Picture a gifted senior tutoring a first-year student. Instead of handing over a blank answer key, the senior explains why each answer is correct and shares hints on common pitfalls and subtle topic links. KD follows the same pattern:
- Teacher model: a heavyweight network such as a very deep ResNet or a sizeable transformer, fully trained for accuracy.
- Student model: a lightweight cousin (e.g., MobileNet or TinyBERT) with far fewer parameters.
- Hard-label loss: the usual cross-entropy against ground-truth labels.
- Distillation loss: an extra term measuring how closely the student matches the teacher’s “soft” outputs (probability vectors or logits), usually controlled by a temperature hyper-parameter that smooths predictions.
Because the student sees both the true label and the teacher’s graded hint, it learns faster, generalizes better, and often outperforms an equally sized model trained from scratch.
Core Algorithms and Variants
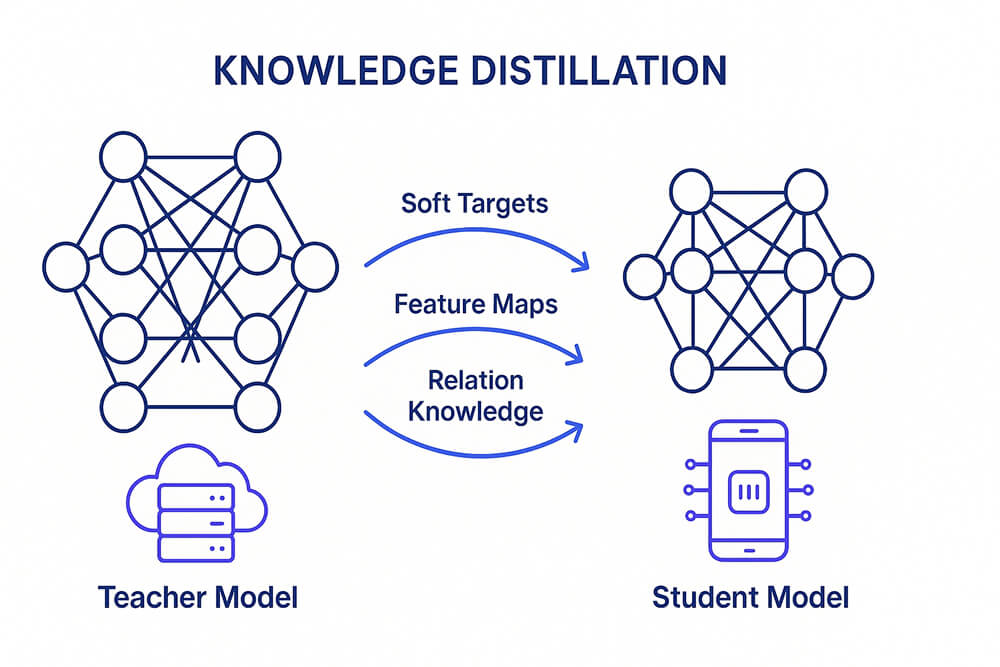
Since KD was first formalized, researchers have created several flavors, each suited to different tasks:
- Logit or probability distillation: The student directly mimics the teacher’s final class probabilities (or pre-softmax logits). It is simple yet effective for image and speech classification.
- Feature-map distillation: Intermediate activations or attention maps are aligned through L-2 loss, attention transfer, or similarity matching, which is crucial for object detection or segmentation where spatial patterns matter.
- Relational KD: Instead of raw activations, the student preserves pairwise distances or angle relationships among samples in the teacher’s embedding space, benefiting face recognition and metric-learning workloads.
- Self-distillation (layer-wise KD): A single deep model uses its later layers to supervise earlier ones, allowing very deep architectures without external teachers and easing vanishing-gradient issues.
- Multi-teacher or ensemble distillation: Several diverse teachers vote; their collective wisdom is fused into one student, boosting robustness in multilingual language processing or multimodal pipelines.
Although stylistically distinct, all variants share a common goal: compress expressive capacity without losing the teacher’s nuanced decision boundaries.
Types of Knowledge and Training Methods
Information passed from teacher to student is often grouped into three buckets:
- Response knowledge: final outputs: probabilities or logits.
- Feature knowledge: intermediate activations, gradients, or attention maps.
- Relation knowledge: structural cues such as similarity graphs or ranking orders among samples.
Delivery style shapes training:
- Offline distillation: Train the teacher first, freeze it, and then train the student with both hard-label and distillation losses. This classic pipeline is reproducible but requires storage for the giant teacher.
- Online distillation: Teacher and student learn simultaneously; the teacher may be a moving average of the student. This approach reduces memory demands and suits continual-learning scenarios.
- Progressive (cascade) distillation: Knowledge flows through a series of ever-smaller teachers. Each hand-off simplifies the target function, often improving the final student when extreme compression is needed.
- Born-again networks: A student equal in size to the teacher is trained, becomes the next teacher, and the cycle repeats. Each generation benefits from softer targets, sometimes boosting accuracy even without shrinking.
The right choice depends on compute budget, deployment latency, the availability of unlabeled data (teachers can pseudo-label vast corpora), and whether engineers can iterate through multiple training passes.
Applications and Practical Benefits
Because KD slashes memory, energy, and latency costs, it now appears in several uses across the industry:
- Mobile vision: Augmented-reality headsets and pocket-sized drones rely on distilled YOLO or RetinaNet detectors to sustain high frame rates without hefty batteries.
- Natural-language apps: Distilled transformers (DistilBERT, TinyBERT, MiniLM, and others) shrink large language models by roughly 40–60% yet retain most of the original accuracy, enabling on-device voice assistants and offline translators.
- Autonomous vehicles: Sensor-fusion pipelines compress multiple heavy networks into a single student, meeting stringent real-time safety deadlines.
- Privacy-preserving ML: Organizations train teachers on sensitive data, then release public students distilled from them. The student reproduces global patterns while leaking less about individual records.
- Ensemble compression: Serving dozens of models is costly; distillation combines them into a single “super-student,” trimming inference costs while preserving ensemble-level accuracy.
- Green AI initiatives: By cutting floating-point operations, KD reduces inference-phase carbon emissions and aligns with sustainability goals.
Beyond raw speedups, KD also acts as a regularizer: learning soft targets that encode inter-class similarity helps students generalize better than peers trained solely on hard labels.
Conclusion
Knowledge distillation has progressed from a clever research trick to a mainstream engineering practice. By allowing a compact student to absorb the nuanced decision boundaries of a larger mentor, KD delivers three big wins-speed, size, and sustainability-without sacrificing accuracy. As state-of-the-art networks march toward unprecedented parameter counts, distillation will remain essential for putting advanced AI into everyday products, from smart glasses and wearables to spacecraft and medical devices. In short, KD proves that in machine learning, less can indeed be more.
