Large-language-model (LLM)-powered summarization has leapt from research prototype to everyday productivity aid in just a few years. By distilling books, meetings, newsfeeds, and even video streams into bite-sized insights, LLM summarizers promise to tame information overload. Compared with traditional human or rules-based techniques, they offer blazing speed, can process much larger contexts than earlier NLP systems, and, when carefully prompted and audited, may achieve greater neutrality. Yet they also introduce fresh concerns: misinterpreting nuance, fabricating details, and reflecting hidden biases in their training corpora.
How LLM Summarization Works and Where It Stumbles
Most modern systems adopt an abstractive approach: the model first builds an internal representation of the source and then generates new, concise prose, rather than copying key sentences verbatim (extractive). Transformer architectures with attention mechanisms excel at tracking long-range dependencies, enabling them to recognize topic shifts, protagonists, and causal chains across dozens of pages.
However, scale is only part of the story. Prompt design, context window size, and retrieval-augmented pipelines all shape performance. Even state-of-the-art models can:
- Lose factual grounding when the context memory is saturated, leading to hallucination.
- Miss minority viewpoints because training data skews toward majority perspectives.
- Over-compress subtle argumentation, stripping qualifiers and hedging language that matter in legal or scientific domains.
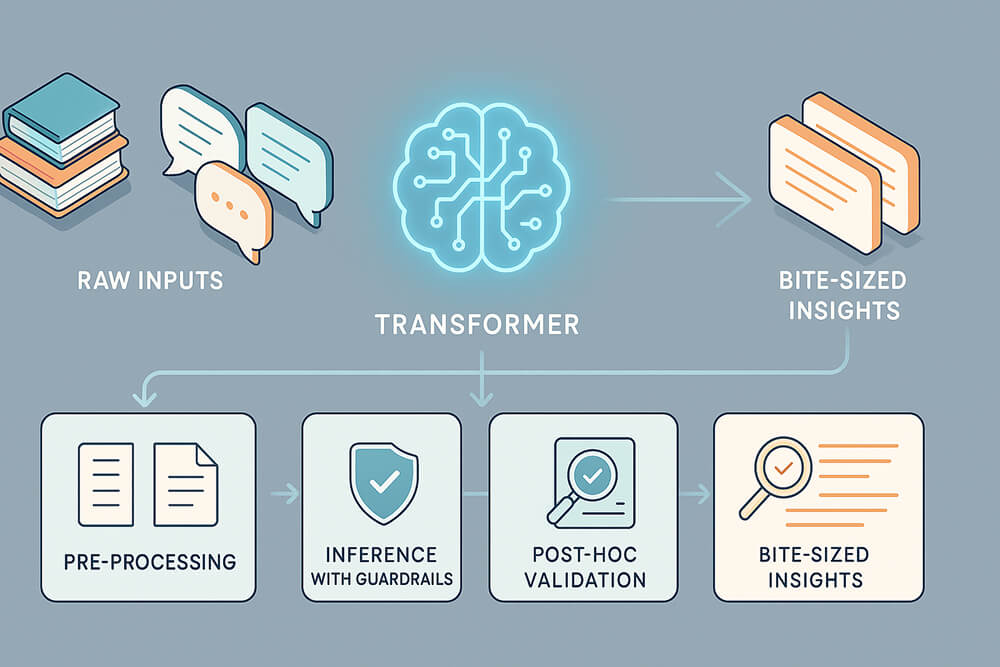
Robust summarization, therefore, requires a carefully balanced workflow: preprocessing (segmenting, filtering), model inference with guardrails, and post-hoc validation against the source text or metadata.
Evaluating Summary Quality: Beyond ROUGE Scores
Classic automatic metrics such as ROUGE, BLEU, and METEOR compare n-gram overlap between a candidate summary and one or more “gold” references. They reward lexical similarity but ignore semantic adequacy or logical consistency, so high scores can mask poor summaries. Recent practice is shifting toward LLM-as-evaluator paradigms. In these, a second model judges the candidate by answering fact-checking questions, rating coverage, and detecting contradictions.
Confident AI’s open-source DeepEval framework, for instance, computes separate scores for coverage (Did the summary include the important points?) and alignment (Is every statement in the summary supported by the source?), then aggregates them into a holistic metric. Early studies suggest this method can reduce some arbitrariness and bias versus string-overlap baselines and often correlates more closely with expert human judgment, though further validation is still needed.
For mission-critical deployments, newsletters, medical notes, and compliance reporting teams increasingly combine automated scores with human-in-the-loop reviews, sampling summaries each release cycle to catch regressions that numeric metrics miss.
Choosing the Right Model: Text vs. Video Summaries
The “best” summarization LLM depends on constraints such as domain, latency, and licensing. Recent open-source contenders for general-purpose text summarization include large instruction-tuned models such as Qwen-3x-30B, GLM-4.5-series, and community variants of GPT-J-120B, each trading off comprehension depth, context length, and compute cost; rankings vary across benchmarks.
Organizations with privacy requirements favor these models because they can run on-premises or behind a virtual private cloud.
Specialized models shine on niche inputs:
- Legal & policy: Llama-family models fine-tuned on legislative corpora show improved retention of statutory citations
- Scientific papers: Specialized Bio- or Sci-GPT derivatives have been reported to preserve numeric results and figure references better than general-purpose models.
- Customer service chats: smaller 7-13B-parameter models fine-tuned on conversational datasets suffice, reducing inference cost.
Video Summarization – The Multimodal Frontier
Text-only summarizers struggle with rich audiovisual cues. New multimodal research bridges that gap. Lee et al.’s 2025 CVPR paper introduces LLMVS, a pipeline that captions frames with a vision-language model, scores importance using a text LLM, and then refines selections with global attention, outperforming purely visual baselines on the TVSum and SumMe datasets.
Approaches such as V2Xum-LLaMA further unify dense and sparse video summaries within a single cross-modal backbone. Such progress points toward summarizers that could eventually condense livestreamed lectures or safety-camera footage closer to real time, though latency and accuracy remain open challenges.
Conclusion
LLM summarization has progressed from rote sentence extraction to nuanced, abstractive condensation across text and video. The field’s next challenges are faithfulness (guaranteeing that every generated statement is source-grounded), personalization (tailoring granularity and tone to individual readers), and efficiency (bringing billion-parameter power to edge devices).
Evaluation frameworks that pair automated metrics with expert sampling, and the emergence of open-source, fine-tune-friendly models, give practitioners the tools to meet these challenges. As multimodal techniques mature, expect summarizers that compress not just what we read but everything we watch and hear, transforming how knowledge is consumed in an attention-scarce world.
