What is the difference between online and offline LLM evaluation?
Written by

Status
answered
Written by
Status
answered
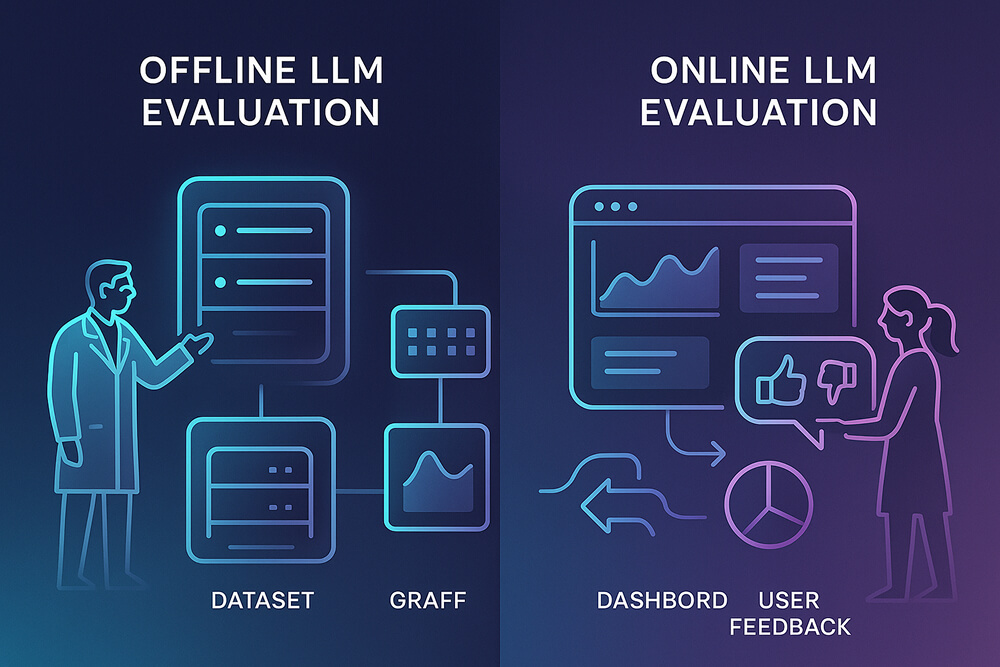
Large language models (LLMs) can supercharge chatbots, search, and knowledge work; yet, a poorly tested release can hallucinate, leak data, or burn budget in minutes. Understanding the differences between online and offline LLM evaluation is now a prerequisite for every team that ships generative AI.
Building on that urgency, evaluation itself comes in two complementary modes. Offline LLM evaluation happens before deployment: engineers run a model, prompt, or retrieval-augmented generation (RAG) pipeline against a fixed “golden” or synthetic dataset to measure quality in a controlled setting. Online LLM evaluation begins after launch, scoring live production traffic or user interactions in real time. The same evaluator logic applies whether a rubric, an LLM-as-judge prompt, or a regression script can be reused locally and then stream scores into production dashboards.
With the definitions established, several practical contrasts emerge:
Because the two modes answer different questions, teams rarely choose just one. After contrasting their traits, consider these decision points:
Union.ai engineers even blur the line by scheduling “offline” evaluations every few minutes, effectively turning them into near-real-time checks.
Choosing the right LLM evaluation metrics is as important as choosing the mode:
Leading LLM evaluation frameworks, such as Arize Phoenix, LangSmith, Braintrust, Maxim AI, and OpenAI Evals, now bundle both modes, allowing teams to score offline experiments and stream online metrics through a single interface. The key is to align framework capabilities, batch processing, streaming hooks, and cost tracking to the metrics that matter for the application.
Used together, online and offline LLM evaluation create a continuous safety net: offline tests catch regressions before code ever reaches staging, while online monitors surface drift, abuse, and cost spikes in real time across live traffic. Turning that safety net into practice means selecting metrics that map directly to user experience and business value, wiring those metrics into a framework that supports both batch and streaming workloads, and automating guardrails alerts, canary rollbacks, and shaded traffic to shorten the time from detection to fix.
Follow those steps, and the team will ship features faster, debug with confidence, and keep every production LLM both useful and trustworthy as data, prompts, and user expectations evolve.


