How Can You Identify Bottlenecks in an Engineering Workflow?
Written by

Status
answered
Written by
Status
answered
Most teams do not notice workflow friction when it first appears. Work still moves, tickets still close, and releases still go out. The problems become apparent later as reviews slow down, handoff delays occur, and engineers spend too much time waiting on others.
That is why identifying bottlenecks should be treated as routine engineering work, not a rescue exercise. Many development bottlenecks are ordinary, repeatable, and easy to miss when people focus only on delivery dates.
When people say delivery feels slow, they often jump straight to assumptions. The backlog may be too large, developers may be distracted, or requirements may be weak. Sometimes these are true, but a better starting point is looking for queues.
A bottleneck usually leaves a visible pile somewhere. Pull requests sit unreviewed for two days. QA waits on unstable builds. A service team becomes the default approver for every schema change. If work enters one stage faster than it leaves, that stage deserves attention.
This is where engineering workflow bottlenecks become easier to see. You are not trying to judge effort in the abstract. You are checking where work accumulates, where it gets reworked, and where it depends on a small number of people.
Teams often track lead time and cycle time, but these numbers alone do not reveal much. A ticket that took six days might have needed five days of real implementation, or it might have spent four days sitting idle between review and testing.
A simple breakdown is usually more helpful than a single big metric.
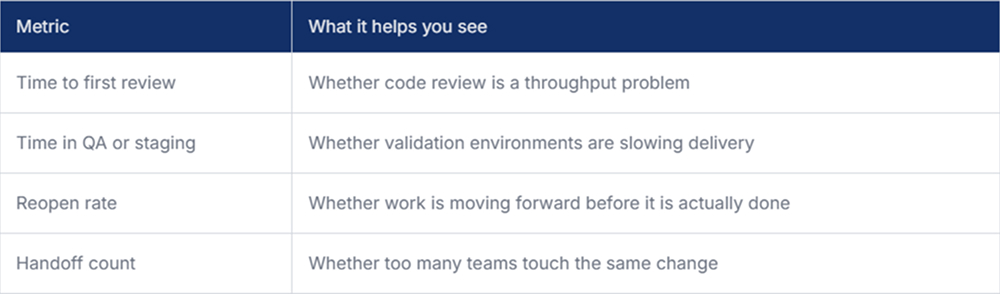
Once you split delivery into stages, software development bottlenecks stop looking vague. You can tell whether the problem sits in implementation, review, testing, deployment, or cross-team coordination. Tools such as Milestone can make those patterns visible across teams and give leaders a clearer view of workflow performance.
Some bottlenecks are not about waiting. They come from doing the same work twice.
A team may finish a feature, then reopen it because the acceptance criteria were fuzzy. Another team may merge code quickly, then spend two more days fixing test failures that should have been caught locally. This kind of churn often gets hidden because the ticket still appears to be progressing.
Useful signals include:
These patterns usually point to developer productivity bottlenecks that sit upstream of coding. The issue may be weak API contracts, inconsistent review standards, or missing local test coverage. The code change becomes the place where the problem is noticed, but not where it started.
Many engineering teams have a few people or systems through which everything flows. That is not always bad. Deep expertise has to live somewhere. The problem begins when one specialist, one repository, or one approval step quietly controls the pace of many unrelated tasks.
You can usually spot this by scanning recent work and asking a few plain questions. Which team is asked to unblock everyone else? Which service causes the most waiting? Which engineer gets tagged on every risky change?
Dependency hotspots often cause engineering workflow bottlenecks, even when individual contributors are working hard. The issue is structural. If five teams need the same platform change before they can continue, local efficiency will not solve much.
A workflow can also slow down because too much work starts at once. Teams sometimes think of bottlenecks only as blocked output, but uncontrolled intake causes the same outcome. Half-finished stories, large branches, and too many parallel priorities make progress harder to see and harder to complete.
This tends to create software development bottlenecks that look like general busyness. Engineers are active all day, but very little is done. That is usually a sign that the work in progress is too high for the capacity for review, testing, and deployment.
A useful check is whether new work starts before older work has a clear path to release. If that happens regularly, the team is feeding the queue faster than it can drain.
Finding bottlenecks is mostly about being specific. Slow delivery is not one problem. It is usually a mix of waiting, rework, and dependency drag spread across a few stages. The useful move is to trace where work actually pauses and why. Once that becomes visible, development bottlenecks are less mysterious and usually much easier to fix.



