How do Mixture of Experts LLMs impact inference speed and model efficiency?
Written by

Status
answered
Written by
Status
answered
A mixture of experts (MoE) model splits a large network into many “experts” and uses a lightweight router to activate only a small subset (often top-1 or top-2) per token. This sparse activation means fewer parameters run on each step while the full model capacity remains available across tokens. In practice, “mixture of experts LLMs” refers to transformer-based systems where select feed-forward blocks are replaced by expert pools under a shared router; this is the core of MoE architecture.
With the definition in place, the performance story centers on compute sparsity. Because only a fraction of experts fire per token, the number of multiply-accumulate operations per step drops significantly compared to a dense counterpart with similar total parameters. The router is a small matrix multiply and softmax, so its overhead is tiny relative to expert MLPs. When experts are distributed across GPUs, their work runs in parallel and returns to the token’s sequence order with a gather step, often yielding lower latency at the same or higher quality level.
A second boost comes from locality. Tokens of a similar type tend to be assigned to similar experts, thereby improving cache reuse within those experts’ weights and activations. This concentrates hot paths, which can further reduce kernel launch diversity and improve effective throughput.
Extending that idea to production, real latency hinges on system details:
Because only a subset of experts is active per token, activation memory scales with the active experts, not the total pool. This keeps peak VRAM lower at a given hidden size. Meanwhile, weight memory can be sharded: each GPU hosts different experts, so the aggregate model capacity scales with the cluster rather than a single device. Techniques such as tensor/sequence parallelism, as well as a quantization stack with MoE, allow teams to serve larger effective capacity per dollar.
Cost efficiency follows: higher tokens-per-second per GPU and the ability to right-size clusters to demand, reducing serving spend. For many workloads, a sparse model with more total parameters can match or surpass a dense model’s quality at similar or lower latency, an attractive trade for production.
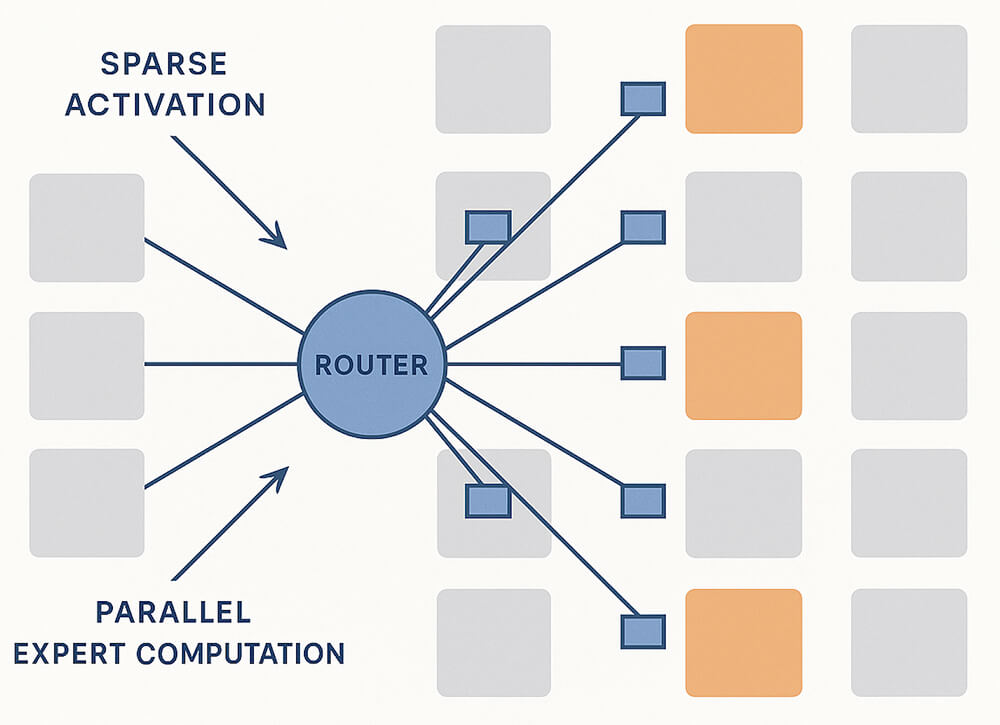
Bridging into operations, “mixture of experts DevOps” concerns revolve around utilization, stability, and observability:
To turn principles into results, several choices matter:
MoE models accelerate inference by activating only a few specialized experts per token while maintaining large overall capacity, yielding strong speed-to-quality trade-offs. Teams that invest in routing balance, network-aware placement, and expert-level telemetry unlock the full latency and cost benefits of (MoE) architecture and modern mixture of experts LLMs.

