Best Practices for Using an AI Measurement Framework
6 min read• Oct 22, 2025
Written by

Milestone Team

Artificial intelligence (AI) is no longer an experiment sitting at the side of engineering. It’s now part of everyday work, writing code, assisting with reviews, running tests, and even shaping planning. As more teams adopt these tools, the question is not how we use AI, but how we measure if it is truly making things better.
An AI measurement framework provides teams with a structured approach to answering this question. It helps check whether AI tools are creating real value, highlights risks that may be hidden, and ensures improvements are sustainable.
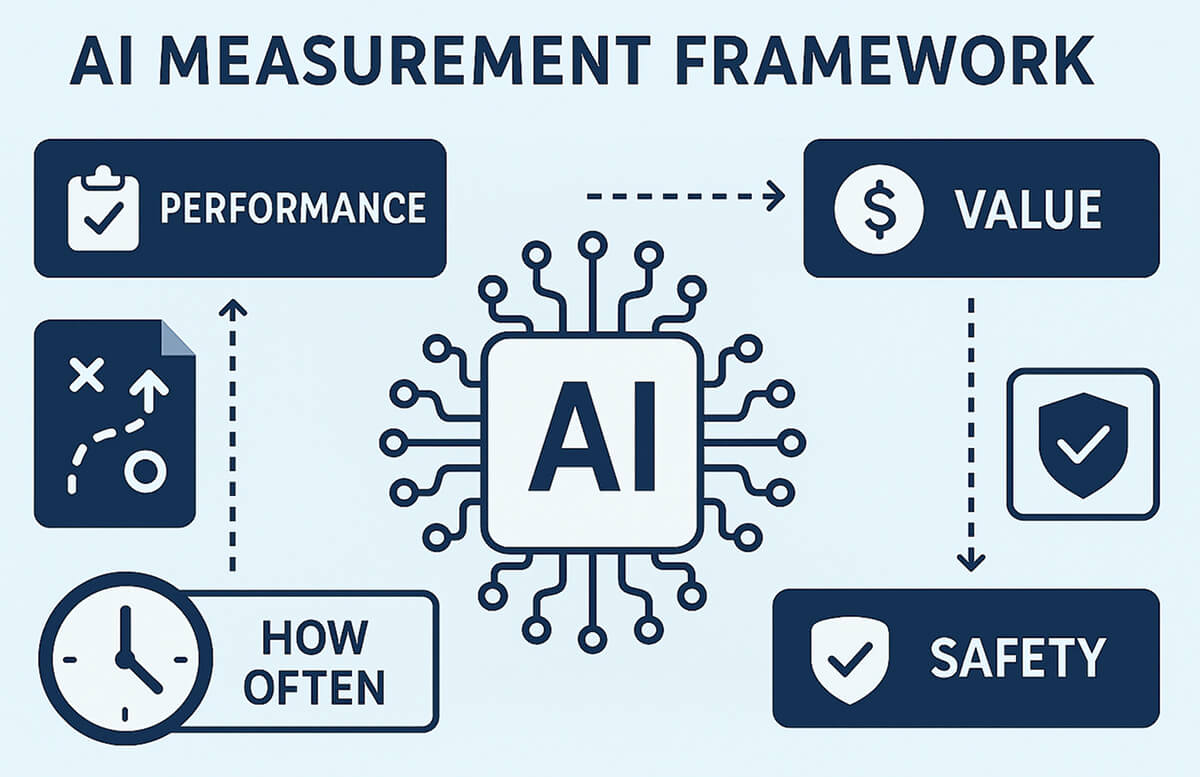
An AI measurement framework is a structured approach to evaluating how AI tools or models perform, the value they bring, and their safety. It provides a clear map of what to measure, how often, and why.
Measurement without direction often creates noise. Before choosing any metrics, define what the organization really wants from AI.
A common mistake is starting with metrics before setting goals. Teams sometimes measure everything, from latency to storage usage, but when asked, “Which of these actually matters for the product?” they struggle to provide an answer.
Over-optimizing a single metric, such as accuracy, can backfire. AI that looks perfect in one dimension may fail in another.
Some teams measure too many dimensions without weighting them. This dilutes focus. The trick is to balance breadth with relevance: 4-6 strong, well-defined metrics are better than 20 half-baked ones.
Engineers must document not just outcomes but also assumptions, data sources, and limitations. Without this, reproducibility decreases, and teams lose trust.
Transparency is also important for regulatory and customer trust. Try explaining to a customer why their loan was turned down by an AI system. If there’s no documentation, you can’t prove whether the decision was fair or if bias slipped in.
Models tested only in clean lab settings rarely survive real-world use.
Extra tip: Some teams run “red-team” tests, intentionally feeding malicious or nonsensical prompts to see how the AI breaks. This type of testing has uncovered vulnerabilities in large models that traditional QA never detected.
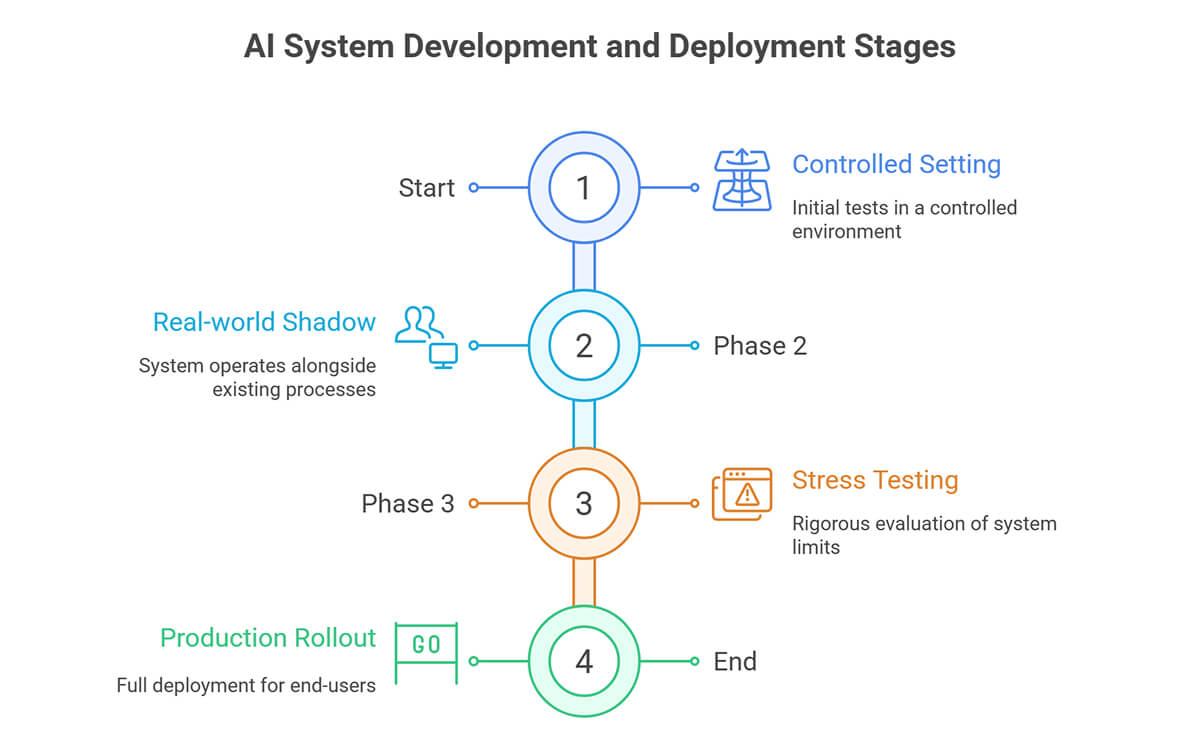
AI is not static. Data drift and model decay are common. Continuous monitoring is just as critical as initial testing.
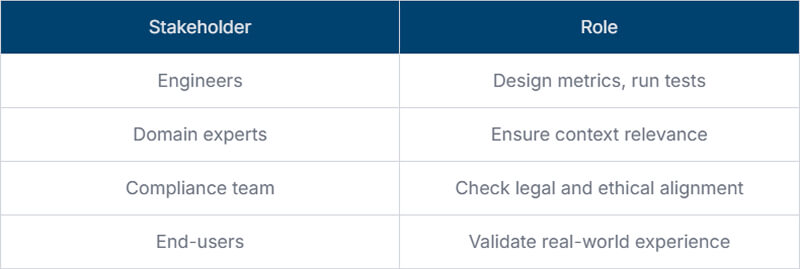
Effective measurement is not only for engineers. A diverse set of voices ensures balanced outcomes.
AI risks and tools evolve quickly. A framework designed two years ago may miss new challenges.
Teams sometimes stick with old benchmarks simply because they’re familiar. The problem is that outdated benchmarks can create an overly positive picture of a model, giving a false sense of confidence.
Many organizations have already built working measurement frameworks. Two leading approaches stand out: DX and LinearB.

Overcoming these requires both technical and organizational discipline.
AI measurement will not stop at simple metrics. Next-generation frameworks will likely include:
Just as DevOps pipelines became standard for software delivery, these frameworks may become a baseline expectation for any engineering team deploying AI at scale.
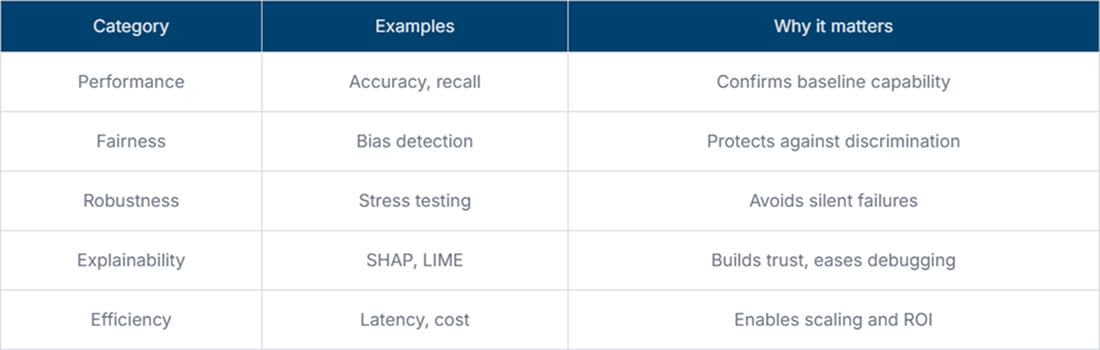
It should track fairness, robustness, interpretability, efficiency, and business impact. Accuracy alone rarely reflects overall reliability.
Review the framework quarterly to catch changing trends and ensure metrics remain aligned with business goals. Run an ad-hoc review sooner if a new regulation, major risk, or new AI tool appears. Do a deeper, full-scale assessment once a year to refresh benchmarks and governance.
Yes. A single framework can cover multiple AI use cases, such as model performance, data quality, fairness, and cost. Because the structure (goals → metrics → monitor → feedback) stays the same, you simply plug in different metric sets: accuracy and latency for performance; completeness and freshness for data quality. Using a single framework avoids tool sprawl, maintains consistent dashboards, and enables teams to see trade-offs in one place.
Automated monitoring handles routine checks. Humans step in for complex cases, ethical tradeoffs, or unusual anomalies.
If done poorly, yes. But frameworks designed with automation in mind actually save time by catching issues earlier and preventing costly rework.
Regulators set the rules for AI fairness, safety, and explainability. A measurement framework provides the audit trails, metrics, logs, and documentation that demonstrate your models comply with those rules. This helps avoid fines and deployment delays.
Popular options include MLFlow for experiment tracking, Evidently AI for monitoring, Fairlearn for fairness metrics, and open benchmarks like MLPerf.
The role of a measurement framework in AI engineering is straightforward but critical. It sets the foundation for building systems that are reliable, explainable, and ethical.
Good practice makes a difference. Clear objectives, a mix of metrics, proper documentation, testing in different scenarios, ongoing monitoring, stakeholder input, and regular updates reduce risk and bring out the best in AI.
On the other hand, the stakes are high. AI decisions are no longer abstract; they affect products, services, and people. That is why engineers and senior engineers need to view measurement frameworks not as add-ons, but as a core part of engineering practice.
Sign up to our newsletter
By subscribing, you accept our Privacy Policy.