A good retrieval system usually fails first in ordinary places, not in the model or the vector database, but in the handoffs between ingestion, retrieval, prompt construction, and response validation. That is why RAG system design is really about controlling how information flows through the entire pipeline.
A RAG prototype can look solid in a demo, then break down under real user behavior. People ask broader questions, mix terms, and expect multi-turn context. That is where the RAG chatbot system design stops being a demo problem and becomes a real engineering one.
Start with the retrieval boundary
The most important early decision is simple: what should the system retrieve, and what should the model infer on its own?
If that boundary is vague, the chatbot starts pulling in too much irrelevant context or relying on model memory when it should stay grounded in retrieved material. In a production setting, that leads to inconsistent answers and harder debugging.
A practical RAG chatbot system design typically separates the flow into four stages: document ingestion, indexing, retrieval, and answer generation. Each stage requires its own controls. Lumping them together makes failures harder to trace.
Chunking is an engineering decision
Chunking gets treated like preprocessing, but it directly affects answer quality. Small chunks help retrieval precision, but they often lose surrounding meaning. Large chunks preserve context, though they also increase noise and token cost.
A better approach is to chunk based on document structure instead of raw character count. Headings, lists, code blocks, tables, and section boundaries usually mean more than arbitrary token windows.
Here is a simple way to think about chunking choices:
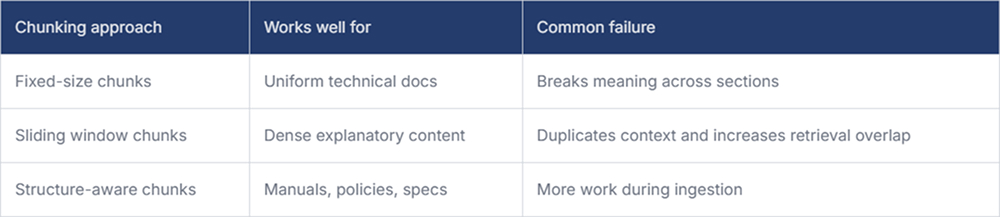
This is one of those areas where RAG system design becomes highly practical. If your source material is internal documentation, preserving hierarchy often matters more than squeezing out a slightly better embedding score.
Retrieval quality depends on metadata
Teams often focus on vector similarity and ignore metadata until late in the project. That usually creates problems once the document set grows.
Metadata helps narrow retrieval before semantic search does the rest. Version, source type, product area, publish date, region, and access scope make retrieval more precise. Without them, the system may surface an outdated answer that is semantically similar yet operationally incorrect.
A retrieval layer should support both semantic matching and structured filtering. That matters when two documents convey similar information, but only one is valid for the user’s role or region.
Useful retrieval signals usually include:
- Source freshness helps avoid answers from retired or superseded documents.
- Document type lets the system treat policy pages, tickets, and API references differently.
- Access scope prevents the assistant from pulling content that the user should not see.
- Conversation context helps follow the user’s current topic rather than treating each turn in isolation.
These are small controls, but together they make a RAG chatbot system design behave more like a dependable internal tool and less like a clever search demo.
Ranking and prompt assembly matter more than people expect
Even when retrieval returns relevant chunks, the answer can still go wrong if the ranking is weak or the prompt is overloaded. Sending the top ten chunks into the model is not a design strategy. It is just deferring the ranking problem to the LLM.
A better pattern is to retrieve broadly, re-rank narrowly, and then assemble only the context needed for the actual question. In many systems, a cross-encoder re-ranker or a lightweight scoring pass improves relevance more than changing the embedding model.
Prompt construction should also stay disciplined. If the system prompt says, “answer only from context,” but the retrieved context is thin or contradictory, the model needs a clear fallback. Otherwise, it fills gaps with plausible language.
Evaluate failure modes, not just happy paths
Much early evaluation focuses on whether the system can answer known questions. That is useful, but not enough. The harder question is how the system behaves when retrieval is partial, stale, conflicting, or empty.
A solid evaluation set should include:
- Questions with no valid answer in the corpus
- Queries using synonyms or internal team language
- Requests that require combining two or three retrieved sources
- Follow-up questions that depend on conversation history
This is where RAG system design becomes a reliability problem, not just an AI problem. You are designing for ambiguity, drift, and incomplete knowledge, not just relevance scores. For teams trying to measure whether these systems are actually improving engineering work, platforms like Milestone help link GenAI adoption to workflow visibility and ROI.
Conclusion
The strongest RAG systems are usually not the ones with the most complex architecture. They are the ones with clean ingestion, sensible chunking, retrieval filters that reflect the actual document set, and prompts that fail safely.
That is what makes a system usable over time. Not just that it can answer, but that you can understand why it answered that way.