The Hidden Costs of Poor Code Quality And How to Eliminate Them
Written by

Status
answered
Written by
Status
answered
A 2018 Stripe and Harris Poll report revealed that developers spend nearly 42% of their week dealing with technical debt and poor code (including 3.8 hours on debugging “bad code”). That inefficiency represents an estimated $85 billion in lost productivity each year.
The impact of bad code does not end with poor practice; it ultimately leads to extra debugging, slower reviews, riskier releases, and rising incident load. In this article, we will discuss the negative impact poor code has on teams and what engineers can do to prevent it from becoming a bigger issue.
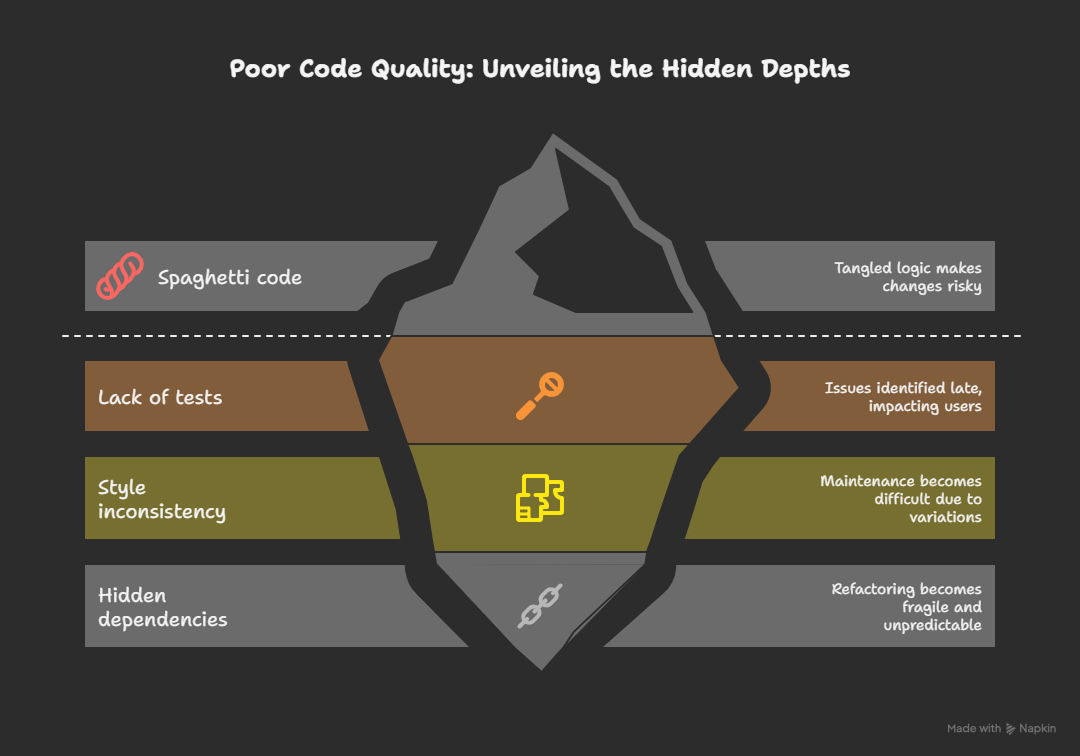
The term ‘poor code quality’ encompasses not just the odd typo or forgotten comment, but far more systemic issues. It covers the most important aspects of software engineering: how code behaves when it is changed, when deadlines are tight, and when multiple people are working on it at once.
Bad code tends to be fragile, risky, and even dangerous to handle. It slows down the process, introduces errors, and even minor changes can feel like a gamble. You’ll often see it in forms like:
Clean, testable, and well-organized code allows teams to:
This is why code quality management is important. It’s the foundation of reliable, sustainable software development.
Poor code quality doesn’t always result in failure, but it ends up costing teams subtly over the long run. Below, we’ll break down where these hidden costs come from and how they impact your team and product.
Messy, unclear, or tightly coupled code means that developers tend to spend more time trying to understand it instead of writing new logic. This particularly damages onboarding, where recruits struggle to get up to speed. Even experienced engineers find themselves stuck in cycles of reading, tracing, and testing before they can safely make a change.
Research from CodeScene shows that:
In these environments, adding a small feature can take days instead of hours.
Badly written code is fragile. Once it breaks, it is not at all a straightforward thing to fix. When there is no good test coverage and structure, it all looks like a guessing game every time a bug is fixed. No matter how minor a problem may seem, it can lead to a series of far-reaching ripple effects.
What this looks like in real terms:
Example cost formula:
And that’s just the engineering time. It doesn’t include late-night deployments, where developers scramble to fix broken features before release. Or the time support teams spend handling frustrated users, chasing tickets, and feeding issues back to engineering, creating a constant loop of firefighting.
Not all bad code starts out bad; often it’s the result of time pressure. Quick fixes, hardcoded values, and one-off logic are used to meet deadlines, but are rarely revisited later. Over time:
This is how you end up in a debt trap. New features slow to a crawl because the foundation can’t support change. Even small improvements require major effort.
Bugs happen. But in low-quality codebases, they’re more frequent and more dangerous. Lack of testing, unclear logic, and unpredictable side effects make it harder to catch issues before they reach production. This results:
When poor code quality turns every sprint into damage control, team motivation drops fast.
According to the 2024 MediaWiki developer survey, 66.5% of developers reported that poor code quality negatively affected their productivity, while 70% pointed to technical debt as a direct source of disruption.
Every bug fix, refactor, or delay caused by bad code is valuable time lost on development. The real loss is in what could have been delivered: better features, faster releases, and more competitive products.
What poor code quality prevents:
Innovation slows down because engineering time is locked up in maintenance. And the longer teams wait to address quality issues, the more opportunities they miss.

Once you understand the damage caused by poor code quality, the next step is learning how to spot it. These issues don’t always show up clearly. They tend to build gradually, quietly dragging down team efficiency and product stability.
Here are some common red flags to watch for:
It is one thing to identify the signs, and another to act upon them. Teams should make iterative improvements during development before it’s too late.
Through these steps, teams can slowly decrease friction, increase stability, and improve the ease and safety of working with the codebase.
Although no amount of technology can ensure clean code, the right tools and processes can enable teams to identify problems early, be more consistent, and improve over time.
Sample tools that support high-quality development:
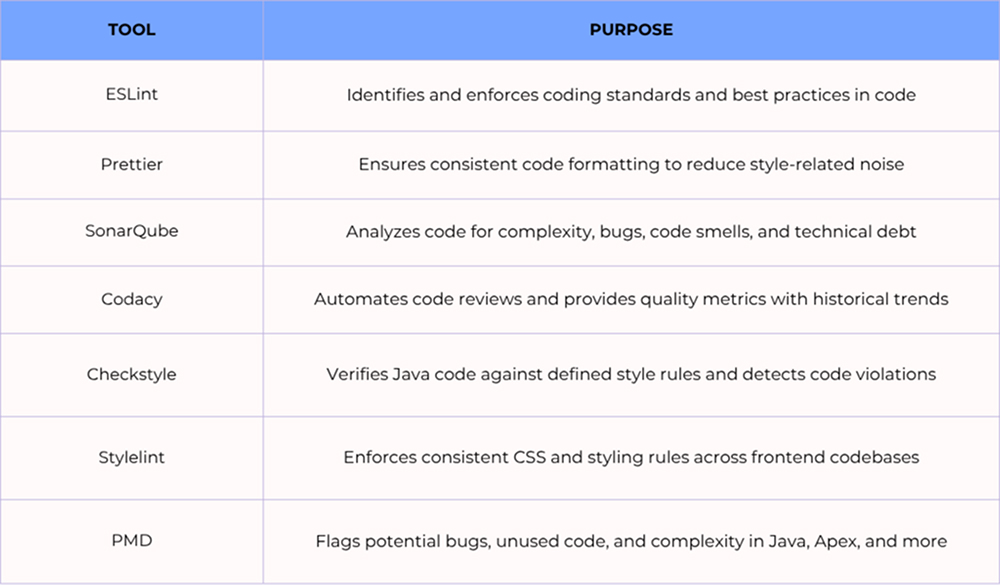
These tools, when combined with considerate engineering practices, allow teams to uphold high standards and identify problems before they are passed on to users.
One of the biggest myths in software engineering is that code quality is optional. In reality, it’s a multiplier; it speeds up delivery, reduces risk, and supports long-term growth. The hidden costs-slow development, rising maintenance, technical debt, burnout, and missed opportunities-don’t just add up; they compound over time.
Improving software code quality isn’t about perfection. It’s about making smart, intentional decisions that help teams move faster and build more reliably. It’s not overhead; it’s an investment that pays off.
Here’s your takeaway:
Let’s build code we’re proud of, one commit at a time.


