How does code coverage improve software quality?
Written by

Status
answered
Written by
Status
answered
Code coverage is among the most visible metrics in modern software testing. It reports what percentage of the source code executes when automated tests run. Although no single figure can guarantee defect-free software, tracking and acting on coverage data can dramatically elevate product quality, reduce maintenance costs, and accelerate delivery.
Coverage tools instrument compiled byte-code or source lines and record which structural elements are exercised. The most common measurements are line, branch, and function coverage. If a project has 1,000 executable lines and tests cover 850, the line coverage is 85%. Branch coverage goes deeper, confirming both the “true” and “false” paths of every decision. Together, these perspectives show how much logic a test suite truly explores.
Teams use coverage as a feedback loop. When a pull request reduces overall coverage, reviewers immediately spot untested logic. A rising trend, on the other hand, signals healthier engineering habits. Overlaying coverage with other software quality metrics, such as defect-escape rate, mean-time-to-restore (MTTR), or code churn, helps leaders judge whether testing investments translate into more stable releases.
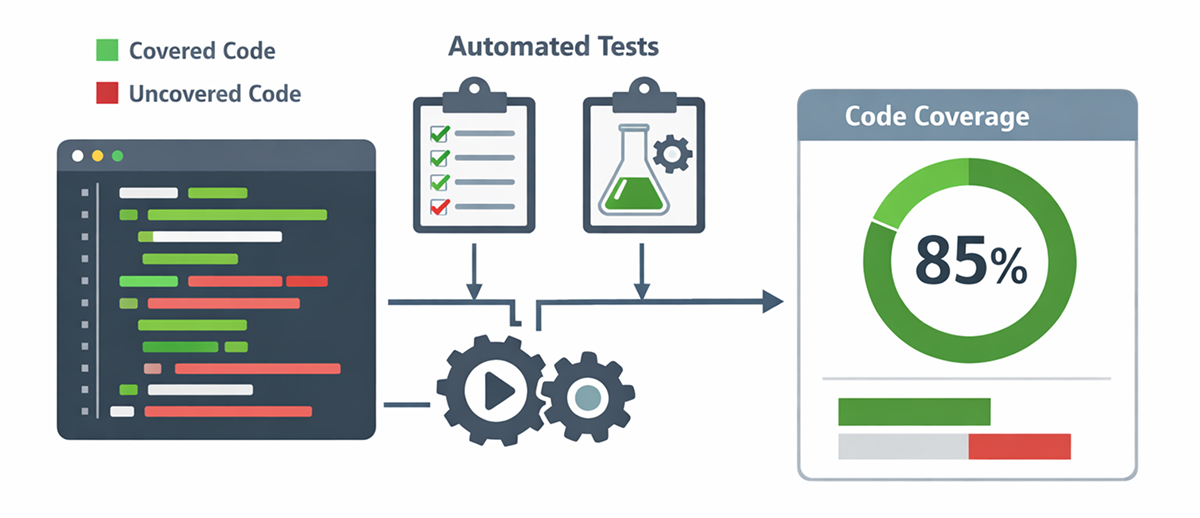
Before diving into specific advantages, it helps to frame coverage as a catalyst rather than a cure-all. High-quality coverage data gives teams insight into where tests are effective, where risks still lurk, and how architecture evolves under the pressure of real-world change.
Red bars in a report highlight functions that never run under test. These blind spots often hide edge-case bugs that would otherwise surface only in production.
Achieving high coverage for a monolithic, tightly coupled class is hard. Developers naturally refactor bulky methods into smaller, single-responsibility units that are easier to exercise, yielding cleaner architecture.
With broad coverage, the likelihood that a change silently breaks critical behavior drops sharply. If a developer removes essential logic, at least one test is likely to fail, catching the defect long before customers notice.
Teams modernizing legacy code often adopt a “cover-and-modify” strategy: write tests around existing behavior until coverage reaches an agreed-upon baseline (for example, 70%), then refactor with confidence. The numeric target keeps the initiative on track and is easy to communicate.
Despite its benefits, code coverage can be misread or misused. Understanding its blind spots keeps teams from mistaking raw percentages for true confidence and ensures effort is focused where it genuinely improves reliability.
Treat coverage as a leading indicator, not the sole definition of “done.”
To transform coverage numbers into tangible quality gains, teams should adopt a few proven habits. The guidelines below help you set meaningful targets, automate feedback, and verify that tests protect real behaviour, not just lines of code.
When used wisely, code coverage evolves from a vanity statistic to a catalyst for higher-quality software. It illuminates untested logic, nudges teams toward cleaner designs, and gives stakeholders confidence that new features will not break existing ones. Coupled with strong assertions, risk-based targets, and complementary software quality metrics, coverage helps engineering teams deliver resilient, maintainable products without slowing innovation, while still hitting ambitious release schedules and sustaining a predictable cadence of feature delivery.

