Come on in, the water’s fine.
Why One-Shot AI Recreates Waterfall
Written by

Stephen Barrett
A growing body of thought in agentic AI suggests that software systems can be specified upfront in natural language and then executed by large language models. This framing implies a shift away from traditional engineering effort toward specification-driven development. This paper argues that this paradigm is not new. It represents a re-emergence of the waterfall fallacy: the belief that complex software systems can be fully understood and defined prior to construction.
In contrast, real-world software systems are not implemented from complete specifications. They are discovered through the act of building. The process of construction reveals constraints, edge cases, and interactions that cannot be fully anticipated in advance. One-shot, specification-driven approaches fail not because models are insufficiently capable, but because they assume knowledge that does not yet exist.
“Come on in, the water’s fine.”
This is the implicit promise behind one-shot AI development and long-horizon agentic execution.
Whether framed as a single prompt that generates a system, or as an autonomous agent operating over extended periods from an initial specification, the underlying assumption is the same: that intent can be sufficiently captured upfront to guide correct system formation without continuous discovery. In this context, “specification” refers to the natural-language description of intent that drives implementation in practice, not to formal, mathematically rigorous system specifications. Systems can be described in natural language, handed to a model, and brought into existence in a single step. The role of the engineer shifts from builder to specifier. Natural language replaces formal design artifacts, and execution becomes a function of model capability rather than engineering iteration.
The appeal is obvious: faster development, reduced need for deep technical involvement, and the collapse of complex engineering into a single act of specification.
This promise rests on a critical assumption: that the system to be built is already understood.
This framing assumes that the problem of understanding the system has already been solved.
This assumption is not new. It mirrors the core premise of the waterfall model of software development.
Waterfall separates defining a system from building it. Requirements are specified upfront. Implementation is treated as a mechanical translation of those specifications into code.
The modern agentic framing reproduces this structure:
Both models rely on the same belief: that the system can be fully known before it is built.
This belief is not just optimistic. It is historically disproven.
The failure of waterfall was not a failure of discipline, but of epistemology. It assumed that a system could be fully understood before it was built.
But it also exposed a second, less discussed failure: the Manager’s Fallacy-the tendency to mistake specification for understanding. In the traditional waterfall model, the manager (or stakeholder) specified the system and treated that specification as the primary source of understanding. Engineers resisted pure specification-driven models because they experienced firsthand how incomplete those specifications were. The real work of understanding the system did not happen in the specification phase; it happened in resolving the gaps and contradictions during construction.
As the industry moved to agile, the discipline of upfront specification was largely abandoned – but so was the appreciation for how difficult specification actually is.
The result is a re-emergence of the Manager’s Fallacy in a new, accelerated form.
Modern AI tooling lowers the cost of expressing intent, creating the impression that vague or partially formed ideas can be translated directly into working systems. The subtle shift today is the belief that the translation from specification to design happens automatically. Because the AI rapidly generates code, the weakness of the original specification remains invisible at the point of declaration. It is no longer treated as something that must be actively resolved by human engineering.
This introduces a form of epistemic overconfidence: the belief that one understands the system well enough to specify it, even to deploy it, when in fact the understanding is incomplete. It is structurally similar to a Dunning-Kruger effect in engineering contexts. The tools amplify confidence without increasing depth of understanding.
A practical example can be seen in high-profile security failures where systems were deployed rapidly (a rush to premature specification) under the assumption that critical details were already understood. In many such cases, sensitive customer data was exposed not because engineers lacked capability, but because critical assumptions about authentication, access control, or data handling were incomplete or incorrect. These were not just known risks left unresolved, but unknown unknowns, constraints and failure modes that were never anticipated, and that would normally surface only through the act of building and testing the system. They emerged only when the system was exercised under real-world conditions, often by attackers rather than during development.
While often discussed in terms of “one-shot” generation, the same failure mode applies to long-horizon agentic execution. Systems that are given an initial specification and allowed to operate autonomously over extended periods inherit the same core assumption: that the specification is sufficiently complete to guide correct behavior over time.
In long-horizon systems, the problem compounds. Even if a specification is initially sufficient, it degrades over time as the environment, data, and system context evolve. A static specification cannot remain correct in a dynamic system. Without continuous discovery, drift is inevitable.
The core issue is not delegation itself, but the loss of challenge that normally forces specifications to be refined. When work is delegated to an LLM, the system continues to produce coherent outputs and implicit signals of success, even when the underlying assumptions have not been tested. The specification is no longer pressured by reality; it is stabilized by narrative.
In this sense, agentic systems do not remove the need for discovery. They remove the signals that discovery has not yet happened.
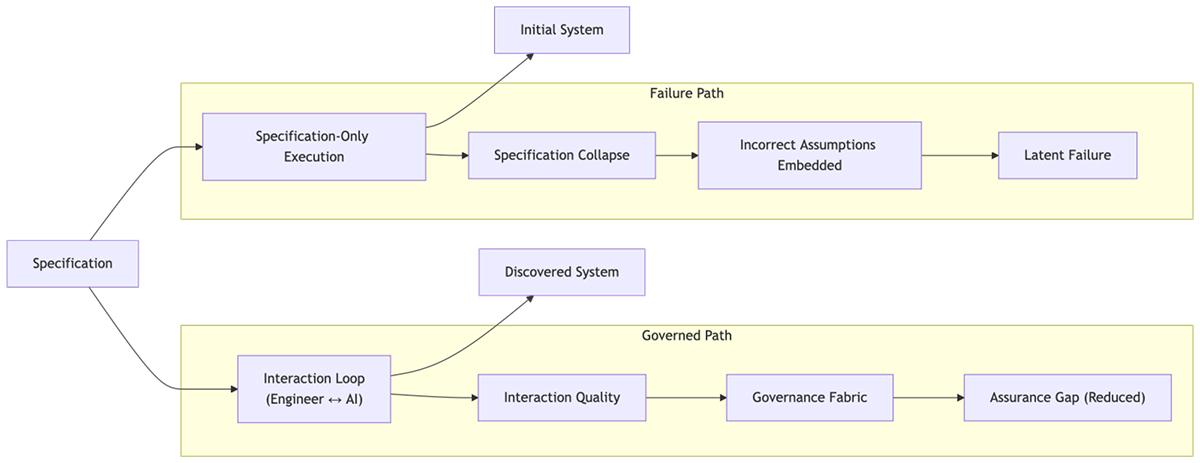
This pattern can be understood as a form of Specification Collapse: the assumption that the act of specifying a system is sufficient to produce a correct implementation, despite the absence of the discovery process required to validate those specifications.
One-shot and long-horizon specification-driven systems fail for the same reason waterfall failed.
Specifications encode beliefs about the system. These beliefs are incomplete, inconsistent, and untested against real conditions.
In iterative engineering, these flaws are surfaced and corrected during development. In one-shot systems, they are embedded directly into the output.
The result is not simply error. It is the freezing of incorrect assumptions into the system.
This is not a limitation of model capability. It is a consequence of removing the feedback loop through which systems converge toward correctness.
This does not imply that one-shot generation is universally ineffective. A large and growing portion of software falls into well-bounded domains where patterns are stable, constraints are known, and uncertainty is low. In these contexts, specification-driven generation can be highly effective.
The failure arises when this success is extrapolated to complex, real-world systems where uncertainty dominates.
This raises a practical question for engineering teams: where does specification-driven generation remain effective, and where does it become risky? While well-bounded domains with stable patterns are well suited to these approaches, the boundary is not fixed. As model capabilities improve, it shifts. Defining this boundary more precisely is an important area for further work.
The role of the engineer is frequently mischaracterized. It is tempting to see engineers primarily as implementers: people who take a specification and turn it into working code. Under this view, improvements in code generation naturally reduce the need for engineering effort.
But this framing misses where the real work happens.
Engineers are not valuable because they write code. They are valuable because they resolve uncertainty. The act of building is not just execution; it is where assumptions are surfaced, tested, and refined against reality.
In practice, this work is continuous. As systems take shape, engineers detect when assumptions break, identify mismatches between intended and actual behavior, and adjust abstractions in response to emerging constraints. The system is not simply being implemented-it is being understood.
This leads to a more important point: the hardest part of building software is not the act of implementation. It is determining what should be built in the first place.
System architecture, functional boundaries, and specification are not prerequisites to engineering. They are outputs of it.
Engineering is the work that occurs between an abstract goal and its realization in the real world. It is the process by which vague intent is transformed into something that actually works under real conditions.
AI changes the cost structure of this process. It dramatically reduces the cost of execution. It does not reduce the cost of resolving uncertainty.
This creates a dangerous illusion: reducing the role of the engineer appears to reduce effort.
In reality, removing the engineer from the construction loop removes the process by which teams discover what the system actually needs to be. It also removes the primary guardrail that prevents incorrect assumptions from being carried forward into the design.
As engineers are distanced from the act of building, a second-order effect emerges: knowledge decay.
Without direct interaction with the system as it evolves, engineers lose:
This loss is not gradual but compounding.
This is not simply another step up the abstraction stack. Previous abstraction layers removed mechanical detail while preserving causal traceability. AI can obscure the causal link between intent and implementation, detaching engineers from why the system behaves as it does. As engineers rely more on specification and less on construction, their ability to detect incorrect assumptions weakens over time.
In their place, a new role emerges: the manager of specifications.
This role operates at a higher level of abstraction, focusing on describing desired outcomes rather than engaging with the mechanics of how those outcomes are realized. Over time, this leads to a shift from engineering to management.
But management does not produce working systems. It produces descriptions of them.
This creates a structural imbalance: system velocity increases through AI-assisted generation, while oversight capacity declines as engineering intuition degrades. This imbalance is the emergence of an Assurance Gap.
This imbalance is amplified by an asymmetry of effort: AI can generate large volumes of plausible system structure almost instantly, while verifying that structure against real-world constraints remains slow and cognitively demanding. As generation accelerates, the burden of validation does not shrink proportionally.
Crucially, this shift also degrades Interaction Quality. As engineers become less engaged in the act of construction, they are less able to challenge model outputs, leading to a higher likelihood that incorrect assumptions are accepted and propagated.
This interacts directly with specification drift. An engineer who no longer understands the system cannot reliably specify enhancements or corrections to it. As knowledge decays, both the quality of interaction and the quality of specification degrade together.
This is the Manager’s Fallacy expressed in practice: treating specification as understanding, where engineers are no longer participants in the discovery of the system, but managers of its description.
A common counterargument is that modern models can internally iterate, refining outputs before presenting them. This is taken as evidence that human-in-the-loop iteration is no longer required.
Internal iteration is not discovery.
AI can compress the feedback loop, but it does not expand the surface of what is being validated. A fast REPL loop is not the same as discovery; it is rapid local correction within an unexamined global design.
Model-driven refinement operates within a closed context. It lacks exposure to:
Without these external pressures, iteration produces self-consistency, not correctness. Discovery is not just interaction with a system; it is the process of resolving uncertainty with accountability for correctness. AI can participate in exploration by generating scenarios and hypotheses, but without grounding in real constraints and outcomes, this remains a form of assisted exploration rather than true discovery. AI can participate in exploration, but it does not carry responsibility for correctness, nor the ability to determine when assumptions have been adequately resolved.
This reflects a deeper characteristic of LLM systems: they are optimized to produce coherent narratives, not verified analyses. They can assemble outputs that are internally consistent and convincing, even when the underlying assumptions are incomplete or incorrect.
A natural extension of this argument is the emergence of tool-augmented agents that interact with live systems, testing assumptions against real data, environments, and feedback loops. This expands the surface of interaction with reality. However, it does not remove the need for human interpretation. Access to signals is not the same as understanding them. The core challenge remains: determining what those signals mean, and whether the underlying assumptions have been adequately resolved.
Specification improves starting conditions. It does not remove the need for discovery.
A viable model treats AI as a participant in construction, not a replacement for it. The implication is not that autonomy is impossible, but that autonomy must be coupled with mechanisms that continuously test and revise the assumptions it operates on.
In this model:
The unit of progress shifts.
Progress is no longer defined by outputs alone, but by the quality of the interaction that produces them.
The interaction between engineer and model is where:
The collaboration is the system-forming process.
If the interaction between engineer and model is where systems are formed, it becomes the primary target for governance. The need for governance arises precisely because this interaction no longer provides reliable signals when assumptions are incorrect.
In agentic systems, more of the decisive work now occurs pre-commit, before code exists as a stable shared artifact. Traditional governance focuses on outputs such as code quality, test coverage, and production incidents. These are lagging indicators that reveal failure after it has already been encoded into the system. Existing validation systems such as CI/CD pipelines remain essential, but they operate on behavior after execution. The role of interaction-level governance is to surface potential issues before they are encoded. The cost of incorrect assumptions increases with how far they propagate through the system, making earlier signals disproportionately valuable.
This does not require prescribing how engineers should work, but making patterns of interaction visible where they are currently opaque. In practical terms, this means being able to distinguish when work is converging from when it is merely producing coherent output, and to see where assumptions are accepted without challenge. The goal is not to expose internal mechanisms or enforce rigid process, but to make it clearer where assumptions are being accepted rather than resolved.
Within this frame, Interaction Quality is best understood as a diagnostic signal rather than a performance metric. It is not used to evaluate individual engineers, but to identify system-level patterns where assumptions are likely being propagated rather than challenged. It reflects whether the human-AI loop is actively refining uncertainty or allowing it to persist under the appearance of progress. It contrasts high-quality interaction, where plausible but incorrect assumptions are actively challenged, against low-quality interaction, where the model’s output is passively accepted.
Without this visibility, organizations are forced to reconstruct reasoning from downstream artifacts rather than observe it directly. This reconstruction is inherently indirect and often ambiguous, especially when multiple causal paths can produce similar outcomes. By contrast, observing interaction patterns provides earlier signals of instability before they manifest as rework or failure. Without this earlier signal, systems are prone to passing superficial downstream validation while carrying hidden structural flaws that only break under real-world scale and integration.
In this sense, governance of the interaction surface is not a speed bump but a diagnostic layer that determines whether the system is converging toward correctness or drifting. It is the earliest control point in a broader Governance Fabric. If governance is applied only at the output layer, the Assurance Gap inevitably widens. It complements downstream validation rather than replacing it, restoring visibility into how systems are formed rather than simply what they produce.
The specific technical implementation of these diagnostic layers, how development environments and agent systems might capture and interpret these signals, is beyond the scope of this paper. The immediate priority is recognizing that this interaction surface is the correct place to observe and reason about system formation.
The appeal of one-shot system generation is the illusion of collapsed complexity. It suggests that understanding can be replaced by specification. This is incorrect.
Software systems do not emerge from specification alone. They are discovered through interaction with partial implementations under real constraints. AI does not eliminate engineering. It relocates it. What is being relocated is not just implementation effort, but the process of determining what should be built.
Knowing what to build remains the dominant difficulty. AI reduces the cost of execution, but does not resolve the uncertainty inherent in specification. Engineering moves from writing code to governing the interaction between human judgment and machine generation. This shift introduces both opportunity and risk.
The opportunity is acceleration. The goal is not to slow engineering, but to reduce the cost of being wrong. This argument is not a rejection of rapid iteration or early-stage product discovery. In those contexts, speed dominates and the market provides a powerful feedback mechanism. The problem emerges when that same model is applied to systems whose correctness cannot be validated by immediate feedback. The moment software becomes relied upon, the risk model changes.
The risk is the widening of the Assurance Gap: increasing system velocity without a corresponding increase in oversight capacity. Closing this gap requires a Governance Fabric that operates at the level where systems are actually formed.
This broader diagnosis is already informing how teams are beginning to approach this problem in practice, including work we are currently exploring at Milestone.
The interaction between engineer and model is not a peripheral concern. It is the core control surface. The security failures described earlier are not edge cases. They are the natural outcome of systems built without sufficient discovery.
The risk is not that engineers disappear. The risk is that they become detached from the process by which systems are formed, and once detached, they lose the ability to recognize when the system is wrong.
The water looks calm from the shore. Depth is only discovered by getting in.
Sign up to our newsletter
By subscribing, you accept our Privacy Policy.

