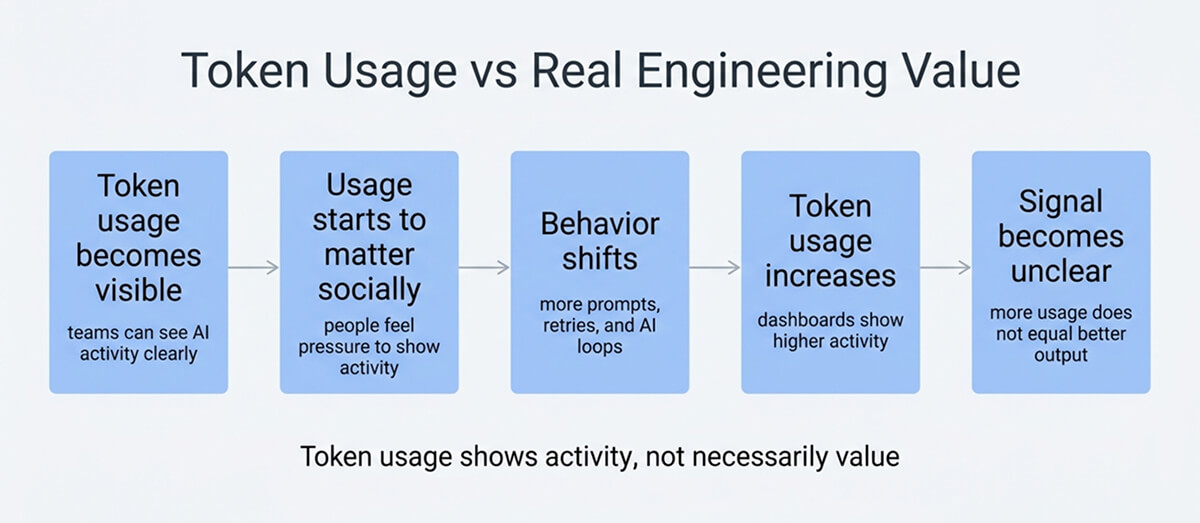
In 2026, tokenmaxxing moved from a niche joke within AI-heavy engineering teams to a real management conversation. Recent reporting described workplaces where token use was visible enough to serve as a proxy for adoption, speed, and even personal output, which is exactly where the problem starts.
The basic idea sounds reasonable at first. Tokens are the units that language models process; usage is easy to count, and the bill shows up quickly enough for finance to care. But easy measurement is not the same thing as a good productivity model, especially when software work still depends on judgment, quality, and follow-through.
What it is really measuring
In plain terms, tokenmaxxing means pushing as much model usage as possible, or at least making that usage visible enough to look productive. That can mean longer prompts, more agent loops, more background tasks, heavier context windows, or simply more frequent calls to coding assistants. Tokens themselves are real and useful telemetry. OpenAI’s documentation breaks them down into input, output, cached, and, in some cases, reasoning tokens, which makes them valuable for cost and systems analysis.
Where teams go wrong is assuming that a countable unit of compute must also be a unit of value. AWS guidance on measuring generative AI in software development recommends looking across deployment velocity, code quality, operational efficiency, team productivity, and business impact. The recent ICSE paper on AI coding assistants makes a similar point from the human side: developer productivity is multi-factorial, and long-term factors such as expertise and ownership do not show up in a single activity metric.
Why token dashboards are tempting
There is a practical reason leaders reach for this metric. Traditional software productivity is hard to measure, but token usage provides an immediate number. Deloitte notes that AI spending is now shaped by token-based consumption, with volatility driven by workload design, prompt engineering, model choice, and infrastructure decisions. If you are running APIs instead of seat-based software, usage becomes explicit in a way that older tooling costs often were not.
That makes token data useful, but only in a narrow way. It is a strong signal for adoption intensity, experiment volume, and cost pressure. It is weak evidence that the code improved, incidents dropped, or customers received anything more reliable. The research and the operational guidance line up on that point: what matters is the shape of work after AI enters the loop, not the raw size of the loop.
- Adoption signal: Shows whether teams are actually using AI tools in real workflows.
- Cost signal: Helps engineering and finance see which systems, teams, or jobs are driving spend.
- Outcome signal: Not reliable on its own, because more model traffic does not automatically mean better software.
The trouble is that once a dashboard becomes visible, behavior starts bending around it. Engineers learn quickly what is rewarded. If the system praises token volume, some people will generate extra drafts, over-expand context, split work into unnecessary sub-agent runs, or keep long-running AI sessions alive just because the burn looks impressive. Recent reporting describes exactly this kind of dynamic, where usage becomes a status display rather than a disciplined engineering tool.
Where tokenmaxxing breaks engineering judgment
Software teams have seen this movie before. Lines of code looked objective. Commit counts looked objective. Story points looked objective once they were flattened into executive charts. Token counts are the same kind of trap, except they also carry direct infrastructure costs. Deloitte’s framing is helpful here: token systems are economic systems, not just technical ones, and demand can rise nonlinearly as workloads become more complex.
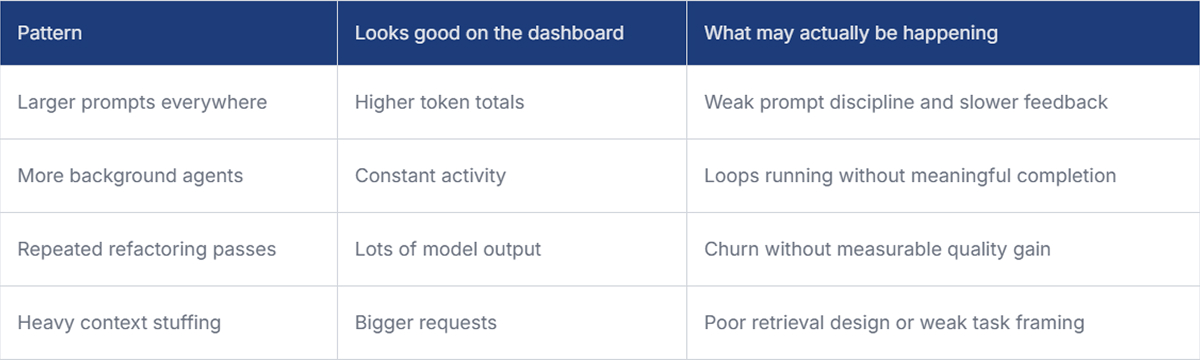
A mature team does not try to suppress usage unthinkingly either. There are real cases where higher usage is justified: broad repo migrations, test generation, large-scale code search, onboarding across unfamiliar systems, or evaluation-heavy release work. The point is not to force minimalism. The point is to align spending with completion quality, elapsed time, and downstream reliability. That is why a single burn chart tells you less than people think.
A safer tokenmaxxing strategy
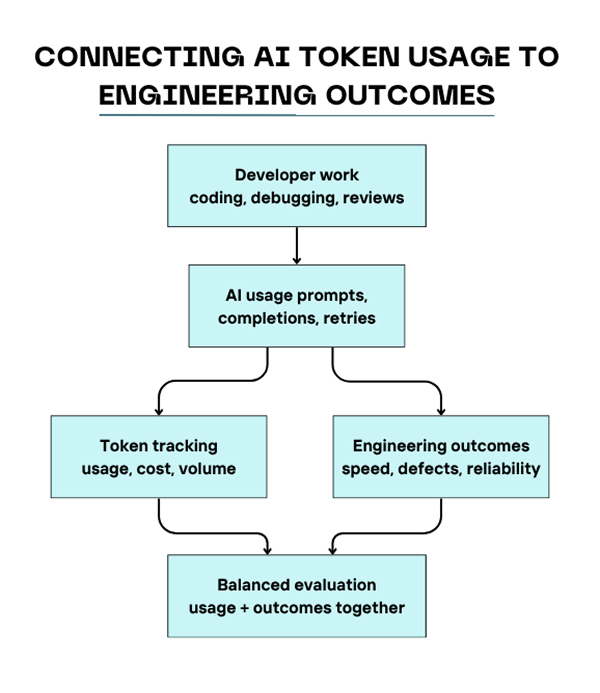
A better tokenmaxxing strategy is to treat tokens as a budgeted input and a diagnostic signal, rather than a personal score. You want enough visibility to find waste, compare workflows, and forecast spend, but not so much that people start optimizing for burn rather than outcomes.
Start with role and task baselines. A platform engineer running migration agents against several services will not look anything like a frontend engineer editing a small component library, and neither should be judged against the same token profile. Then tie usage back to a short list of outcome measures that already matter to the team. If your organization already tracks broader AI productivity metrics, token data belongs underneath that layer, not above it.
- Budget by workflow: Define expected ranges for coding, testing, migrations, support triage, and documentation.
- Review spikes, not individuals: Investigate unusual jumps in spend with traces and task context.
- Join cost to outcomes: Compare tokens against merge time, escaped defects, rollback rate, and incident load.
- Cap unattended loops: Long-running agent chains need stop conditions, budgets, and auditability.
Raw AI token consumption becomes much more useful when normalized against concrete metrics, such as successful task completion, accepted changes, incident-free deployments, or hours saved on repetitive work. That also makes it harder to game. A developer can inflate volume. It is much harder to reduce lower review latency and production mistakes at the same time.
Example: join token usage to delivery outcomes by week
SELECT
week,
team,
SUM(total_tokens) AS tokens_used,
COUNT(DISTINCT merged_pr_id) AS merged_prs,
AVG(pr_cycle_time_minutes) AS avg_pr_cycle_time,
SUM(CASE WHEN escaped_defect = 1 THEN 1 ELSE 0 END) AS escaped_defects
FROM engineering_ai_usage
GROUP BY week, team
ORDER BY week DESC, team;
That kind of query is not glamorous, but it is at this level that governance becomes real. The interesting pattern is rarely “who used the most AI.” It is usually “which workflows consumed more tokens and still produced cleaner merges, faster reviews, or better operational stability.” That is a much harder question, and a much better one.
Final Thoughts
Tokenmaxxing matters because it exposes a real shift in software work. AI usage is now measurable at a level that older developer tooling rarely was, and that will change how teams talk about cost, adoption, and efficiency.
Still, software delivery has not become a contest for who can burn the biggest context window. The healthy teams in 2026 will be the ones that can see token usage clearly, control it deliberately, and keep it subordinate to the things that still count: sound judgment, maintainable code, and fewer bad surprises in production.
FAQ
Why are tech companies using token consumption as a productivity metric?
Because it is visible, immediate, and financially legible. Token usage can show that teams are actively using AI systems, and in API-based environments, it also maps directly to spend. The problem is that it measures activity and scale more cleanly than it measures real value or engineering quality.
What are the risks of using tokenmaxxing as a performance KPI?
Doing so can reward waste, encourage gaming, and shift attention from outcomes to visible burn. Research on AI coding assistants argues for a broader view of productivity, and operational guidance still favors metrics tied to quality, delivery, satisfaction, and business impact rather than a single activity number.
How can developers implement tokenmaxxing strategies?
Do it carefully, only for workflow optimization, not as personal theater. Instrument usage by task type, set budgets for autonomous runs, review spikes with traces, and compare usage against outcomes such as merge speed, defect escape, and recovery performance. Treat tokens as engineering telemetry, not status.