Most RAG systems start with a simple flow. A user asks a question, the system retrieves a few chunks, and the model writes an answer from that context. It works until the question crosses systems, permissions, or multiple reasoning steps.
A multi-agent rag system splits that work among smaller agents. One agent may plan the task, another may retrieve evidence, and another may validate the answer before it reaches the user.
Why Single-Agent RAG Gets Messy
A basic RAG pipeline typically follows a single main route. Query rewriting happens once, retrieval runs against one or more indexes, and the model generates an answer from the selected context. The pattern is useful, but it assumes the question is sufficiently clean for a single retrieval pass.
Real engineering questions are rarely that clean. A developer might ask why a deployment failed after a database migration. The answer may require CI logs, migration files, feature-flag changes, service ownership data, and an incident note. Some of that data is structured, while some is buried in tickets or internal docs.
A single agent can still attempt the task, but it may retrieve too broadly or miss important evidence. It might pull logs without checking deployment metadata. It might summarize an incident without seeing that the same service rolled back later.

Multi-agent rag is useful when the workflow already includes different jobs. Planning, retrieval, domain interpretation, validation, and response writing are not the same task. Treating them as one large prompt makes the system harder to test and harder to trust.
What the Agents Actually Do
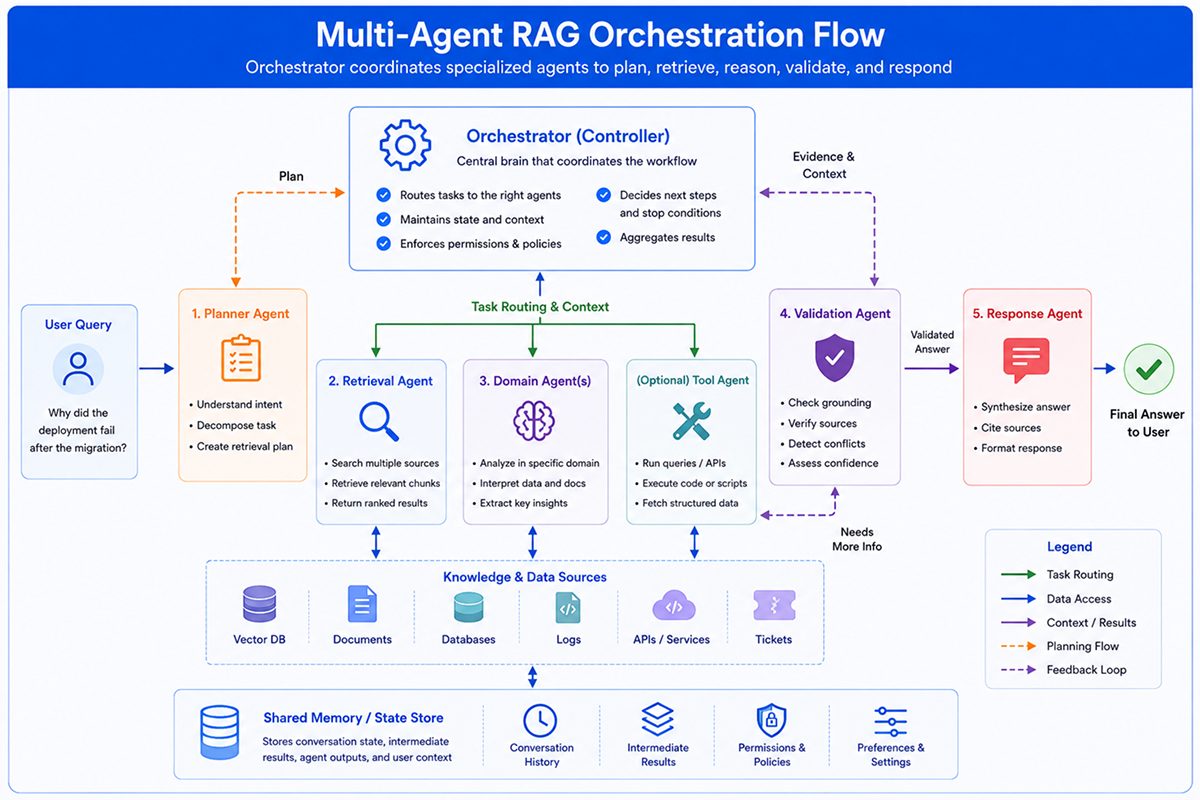
A practical multi-agent RAG architecture usually starts with role separation. The names vary by team, but the responsibilities are familiar.

This is not about adding agents because the design looks advanced. It is about avoiding one vague prompt that tries to do everything. Smaller roles are easier to test, restrict, and debug.
A security retrieval agent can be restricted from exposing raw secrets. A billing agent can be limited to billing documents and schema metadata. A validation agent can reject an answer if it cannot trace claims to evidence.
The Orchestrator Is the Boring Important Part
The orchestrator is less visible than the agents, but it decides whether the system behaves like software or like a prompt chain. It handles routing between documentation search, SQL retrieval, log analysis, and specialist agents.
It can also decide when to ask a follow-up question instead of guessing. That matters when the user leaves out a service name, environment, account ID, or time window. These missing details often change the answer.
State management is another quiet problem. If one agent rewrites the question, another retrieves documents, and a third validates the answer, they need a shared view of what has already happened. Without that, agents repeat work or reason from slightly different evidence.
Retrieval Is Still the Weak Link
Adding agents does not fix weak retrieval. It can make weak retrieval more visible. If the source documents are stale, duplicated, poorly chunked, or lack metadata, the agents will only coordinate around bad inputs.
Chunking still matters. Metadata still matters. Access control still matters. A retrieval agent needs evidence with sufficient context for another agent to judge whether the result is current, relevant, and permitted for the user.
For technical documents, that may mean preserving code blocks, headings, version numbers, and service names. For operational data, it may mean keeping timestamps, owners, environment labels, deployment IDs, and incident status.
Where Multi-Agent RAG Helps Most
The pattern is strongest when the user request crosses boundaries. It is less useful for a small FAQ bot that answers questions from a single, stable set of documents. A simple retrieval pipeline may be enough there.
A support assistant might need product docs, account settings, known incidents, and previous tickets. A developer assistant might combine source code, CI output, observability data, and architecture notes. A compliance assistant might compare policy documents, audit logs, and approval history.
A few practical signs usually show that a team has outgrown basic RAG:
- The answer requires more than one retrieval strategy.
- Different data sources need different access rules.
- The system needs to verify claims before responding.
- The workflow includes handoffs, retries, or escalation.
- The same question needs both structured and unstructured data.
These are engineering signals. When they appear, forcing everything through one prompt becomes fragile. The system may still answer, but the path to that answer is hard to inspect.
What to Measure Before Expanding It
A multi-agent design adds cost and moving parts. Before expanding it, teams should measure whether the extra coordination improves the result.
- Retrieval precision: How often the retrieved evidence is useful for the final answer.
- Grounding rate: How often generated claims can be traced back to retrieved sources.
- Agent handoff failure: How often does one agent pass an incomplete or unusable context to another agent?
- Latency per task: How long the full workflow takes, not just the model call.
- Permission failure rate: How often retrieval returns data the user should not see, or blocks data the user is allowed to use.
These metrics catch real failures. A system that produces better-looking answers while increasing the number of unsupported claims is not better. Milestone can help teams track GenAI impact, adoption, ROI, workflow visibility, and engineering performance without judging quality only from surface-level output.
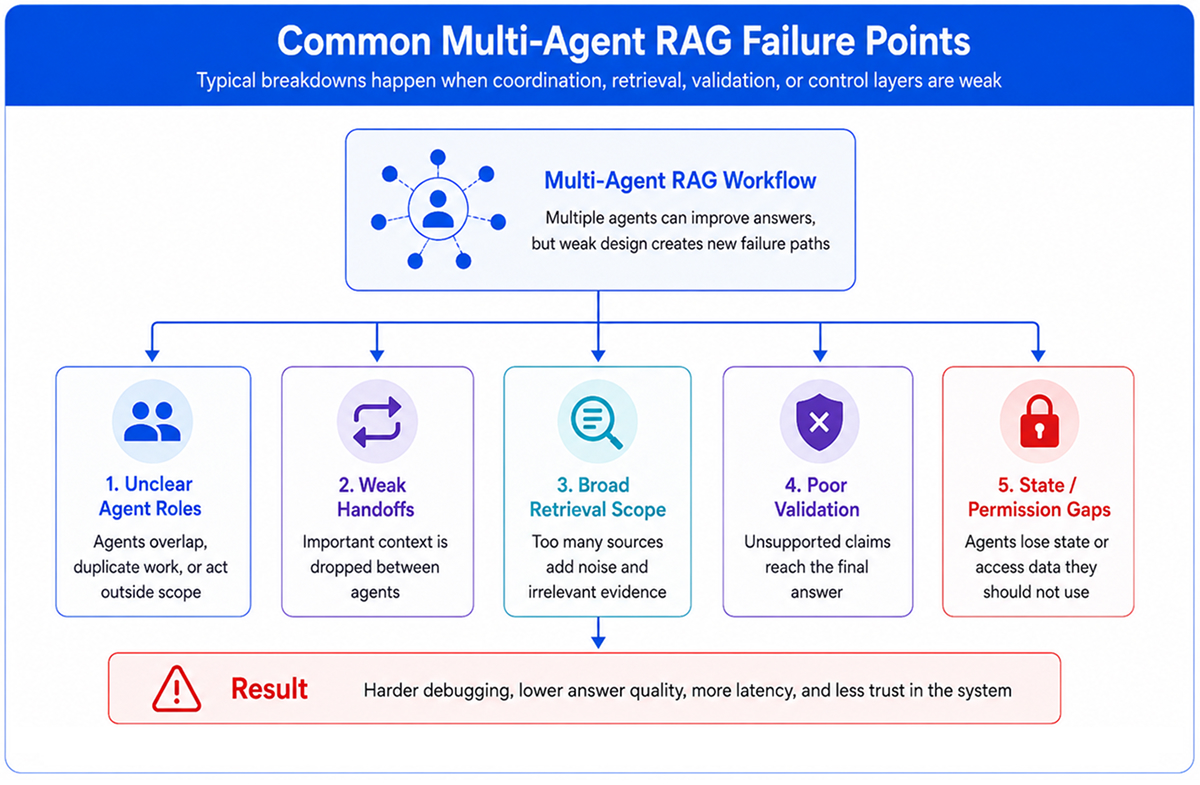
Common Design Mistakes
One mistake is treating agents as independent workers without a shared contract. Every agent should have a clear input shape, output shape, and failure mode. Otherwise, the orchestrator has to guess what happened.
Another mistake is letting every agent retrieve from every source. That creates noise and makes access control harder. Narrow retrieval scopes are usually safer and easier to debug.
A third mistake is delaying evaluation until production is close. Multi-agent RAG needs test cases for multi-hop questions, missing context, permission boundaries, stale documents, and conflicting evidence. Checking whether the answer sounds good is not enough.
Conclusion
Multi-agent RAG is useful when retrieval, reasoning, and validation are too much for one pipeline. It gives teams a way to split the work into smaller, testable parts. The system still depends on clean data, strong retrieval, clear orchestration, and honest evaluation. Without those, more agents only create more places for mistakes to hide.