What Engineering Leaders Need to Know About Agentic Coding Before Adopting It
7 min read• Jun 17, 2026
Written by

Milestone Team

Engineering leaders are now looking at coding agents in a different way. The big change is not that AI can write larger code snippets. It is that newer systems can plan work, use tools, inspect a codebase, run tests, revise output, and move through multi-step tasks with much less step-by-step human prompting. That shifts the discussion out of the “developer productivity tool” bucket and into delivery design, risk control, and operating model design.
That is why adoption should be treated as a strategic evaluation, not a casual experiment. A recent Thoughtworks piece makes the point clearly: the shift to an agent-based SDLC affects organizational structures, people, governance, and culture, not just tooling. That is the frame for this discussion.
Agentic AI coding is best understood as software development in which the model not only suggests code but also pursues a goal through a series of actions. OpenAI’s agent guidance defines agents as systems that independently accomplish tasks on a user’s behalf using tools and guardrails. OWASP similarly describes AI agents, emphasizing reasoning, planning, memory, tool use, and action.
That sounds like a strong autocomplete tool, but the difference is operational. Assistive tools wait for the developer to drive every turn. Agents can take a scoped objective, form a plan, touch several files, run tests, inspect failures, and try again. The human remains accountable but no longer controls every keystroke. That changes how work moves.
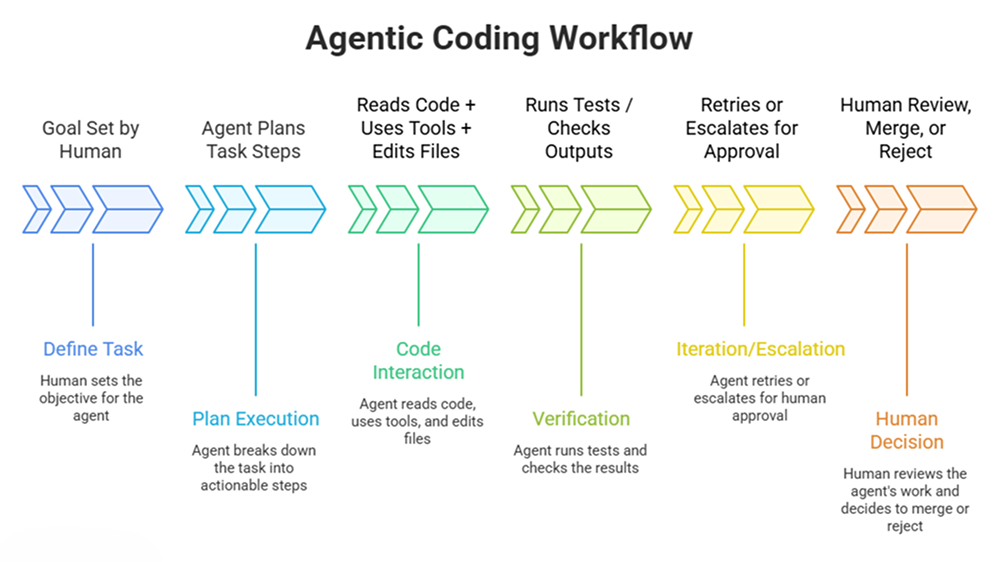
The path has been fairly direct. First came inline suggestions. Then came whole-function and whole-file generation. Then came tools that could inspect a repository, propose edits, and respond to diagnostics. Now the frontier products are explicitly positioned around long-running tasks and parallel work. OpenAI describes Codex as designed for multi-agent workflows, with agents working in parallel across projects, while Anthropic describes Claude Code as reading a codebase, modifying files, running tests, and delivering committed code.
That matters because it changes what “using AI” means inside an engineering org. It is no longer only a faster way to draft code. It can be a faster way to move through parts of the delivery loop.
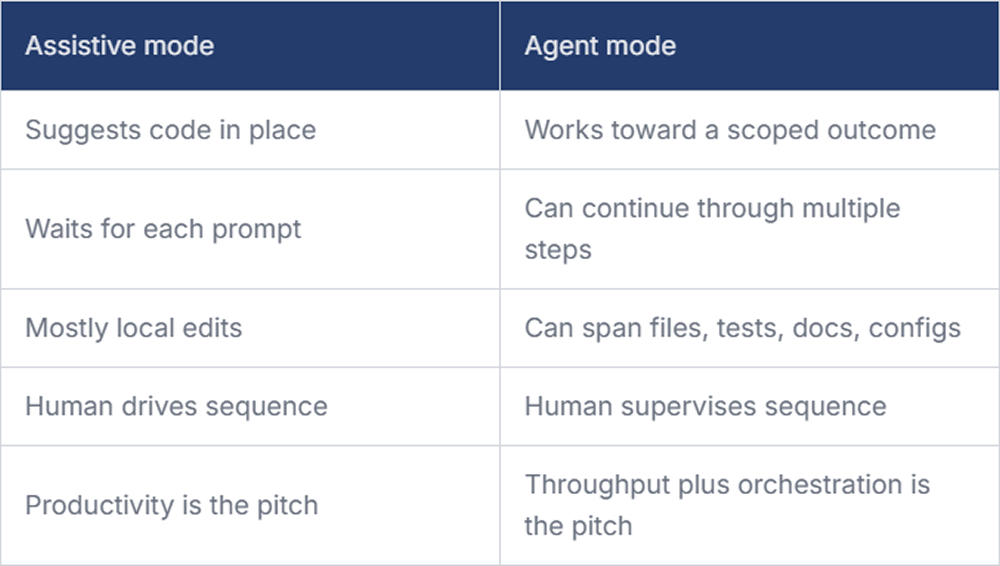
A useful companion article from Thought works frames this as preparation for an agentic software development life cycle, where the real pressure lands on team design, governance, and culture. That is a better framing than the usual “will developers be replaced?” debate. The practical issue is whether your organization can supervise autonomous execution safely enough to benefit from it.
Agentic coding assistants are easiest to understand as delegated execution systems. They can break a task into steps, modify code, validate outputs, and return a change set with reasoning or evidence attached. In the best cases, they behave like a combination of junior engineer, build automation, and workflow runner. In the worst cases, they fail with high confidence and a large blast radius.
The patterns that help most are usually the ones leaders already know how to standardize:
Those are not trivial jobs. They are just easier to evaluate because success conditions are sharper. When the task is fuzzy, the system design is brittle, or the domain is highly regulated, the value drops and supervision costs rise.
A simple control policy often explains the real leadership stance better than any marketing demo:
if task.risk_tier in ["auth", "payments", "prod_config"]:
require_human_approval = True
require_trace_log = True
require_full_test_pass = True
else:
allow_agent_execution = True
require_post_run_review = TrueThe point is not the syntax. The point is that adoption only works when authority, risk tier, and review rules are explicit. OWASP’s guidance calls out human-in-the-loop controls, output validation, and monitoring as first-class controls, and NIST’s AI RMF playbook organizes governance around Govern, Map, Measure, and Manage rather than blind trust in model capability.
A well-scoped agent can shorten the path from intent to candidate implementation. Feature work, tests, and supporting updates can move faster than in a fully manual workflow. The gain is real, but the bottleneck often shifts from writing code to supervising outputs, validating changes, and integrating work safely.
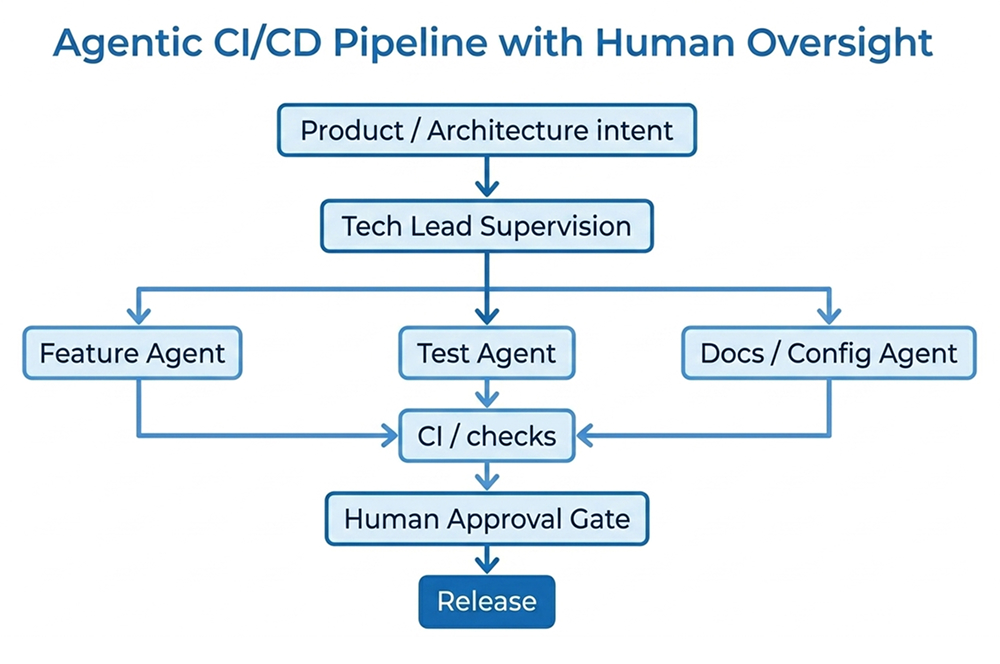
Collaboration changes, too. Instead of every step involving human-to-human handoffs, tech leads define the scope, agents execute within that scope, and engineers review or correct the results. This creates a new layer of supervision between product intent and release.
In practice, teams usually see three immediate changes:
Ownership does not disappear. If agent-generated code causes a defect, the team still owns the outcome, especially the approving human and the process around that approval. Release cycles may speed up, but if review quality, testing, and rollback discipline do not improve at the same pace, the result is usually more rework rather than better delivery.
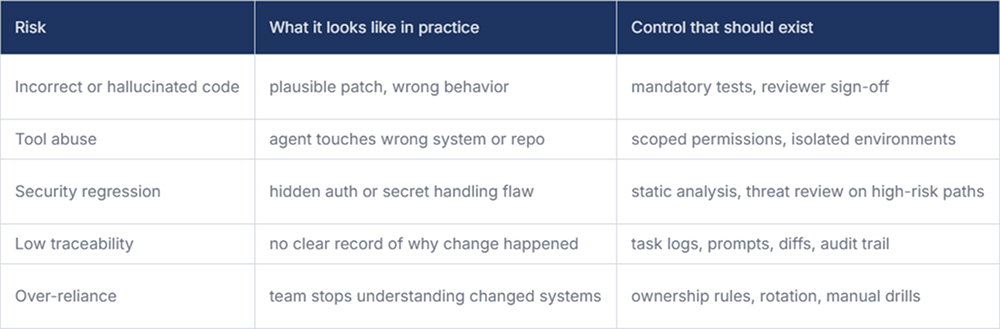
The risk profile is not hypothetical. OWASP’s AI Agent Security guidance highlights prompt injection, tool abuse, privilege escalation, and data exfiltration as major concerns. It’s 2026 Top 10 for Agentic Applications positions these risks as distinct enough to warrant their own operational framework. That should get a leader’s attention, because these are not merely code-quality issues. They are control-plane issues.
A sensible governance model usually needs four parts. Policy defines where agents may act. Approval design defines when humans must intervene. Validation defines the evidence required before merging or releasing. Observability defines what you must be able to reconstruct afterward. NIST’s AI RMF and Playbook are useful here because they push organizations to map context, measure risk, and manage it through explicit processes rather than ad hoc enthusiasm.
This is where many pilots fail. Teams often start with capability and only later try to retrofit governance. The order has to be reversed. High-trust use cases should be earned through evidence, not assumed from a good demo.
Many early rollouts make the same mistake. They measure visible speed and ignore hidden cost. DORA’s current model emphasizes five software delivery metrics and explicitly separates throughput from instability. That is useful here because a faster agent loop can look impressive while quietly increasing rework or failed recovery.
The baseline should mix engineering delivery metrics with agent-specific operating metrics.

The DORA metrics provide a stable backbone: change lead time, deployment frequency, failed-deployment recovery time, change failure rate, and deployment rework rate. Around that, leaders should add local controls such as the percentage of agent-generated changes that need rework, the review turnaround time for agent-authored pull requests, and defect density by task type.
The skills shift is real. Leaders need stronger systems thinking, enough AI literacy to understand failure modes, and tighter operational risk judgment. They do not need to become model researchers. They do need to understand where autonomy ends, where escalation begins, and what evidence qualifies an agent to act in a given workflow.
Org design changes follow quickly. Someone has to own workflow design, tool permissions, evaluation quality, and exception handling. That may not require a brand-new department, but it does require explicit responsibility.
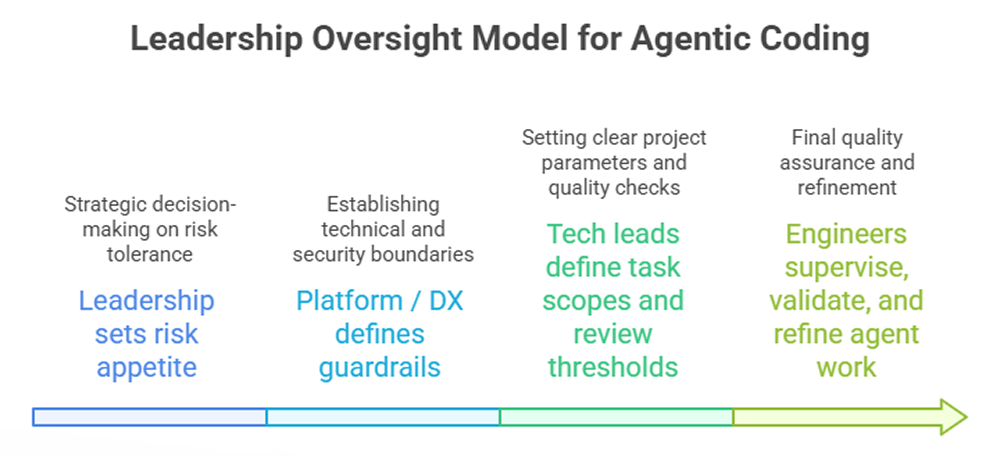
The cultural shift is less dramatic than people say, but it is still meaningful. Teams have to stop treating productivity as a proxy for typing speed. In an agent-heavy environment, productivity increasingly looks like intent quality, task design, review discipline, and feedback-loop strength. OpenAI’s own account of an agent-first build described humans steering while agents execute. That framing is probably the cleanest one available.
Engineering leaders should treat coding agents as a change in delivery model, not a feature upgrade. The real decision is not whether the tools are impressive. It is whether your architecture, review design, permissions model, and incident discipline are mature enough to let them act safely.
The teams that benefit most will not be the ones that give agents the most freedom on day one. They will be the ones who define narrow authority, measure outcomes honestly, and expand autonomy only after the controls prove they can hold.
The main risks are not limited to bad code. They include prompt injection, excessive tool access, data leakage, weak traceability, and over-trusting outputs that look polished but are wrong. Leaders also risk causing confusion during the rollout if ownership and approval boundaries are left vague.
Start with risk tiers, not feature excitement. Define where agents may act, what systems they can touch, when human approval is mandatory, what evidence must be logged, and how exceptions are audited. NIST’s Govern, Map, Measure, and Manage model is a practical structure for that work.
There is no universal percentage, but anything touching production logic, auth, payments, infrastructure, or regulated data should trigger a full review. Early in adoption, many teams should review nearly all agent-authored changes. Sampling only makes sense after strong evidence shows low-risk categories remain stable.
Track delivery speed and instability together. Use DORA-style measures such as lead time, deployment frequency, recovery time, and change failure, then add local indicators like rework rate, escaped defects, agent success rate, and review latency for agent-generated changes. Faster output alone is not proof of improvement.
Three become especially important: systems thinking, operational risk judgment, and workflow design. Leaders need to define safe task boundaries, supervise human-agent collaboration, and build scalable review loops. The job shifts away from monitoring typing effort and toward managing intent, controls, and evidence.
Sign up to our newsletter
By subscribing, you accept our Privacy Policy.